








IBM零售垂直领域合伙人陈果在朋友圈转发了一篇文章,题目叫《Artificial Intelligence in Retail》,讲述的是人工智能在零售领域里的应用。
其中的第一条就是门店选址的最优化。因为从古至今,线下店策划最先考虑的因素就是店铺的位置。文章指出,采用人工智能的方法,结合历史销售数据,人口经济数据,到竞争者的距离等数据可以把选址模型推到一个新的高度。作为在这一领域打拼多年的我,觉得有必要对这一话题展开讨论。
AI在选址的应用并不是一个偶然,它是随着技术的发展和行业人才的变化,在最近这一年突然变成了一个火热的话题。
在美国,传统用地图和数据做零售企业做选址和市场的人,大多是地理系毕业的,他们有着丰富的地理信息系统软件操作能力和对地理模型的理解。选址的模型多半采用空间交互模型这一地理人最容易理解的模型。最经典的组成部分莫过于距离衰减模型。
此外传统的统计学范畴的回归模型和房地产从业者常用的近似模型,也是被市场所接受的。随着近年来地理信息学科的教育走向更加交叉的领域,特别在商学院的市场营销/财务运营管理等学科里渗入,越来越多的非地理人进入到这一领域。
他们有着基本的概念,但是没有很多地理信息系统软件操作的经验。对他们而言,最理想的事情就是在地图上点个点,然后系统告诉他们预测的结果就行了。其他那些复杂的操作,对他们而言是没有意义的。
在这种情况下,选址的软件和模型,就需要足够的智能。就在这个时候,人工智能,机器学习的概念,突然到了风口,那么不难想象,在短短的时间里,大家都开始谈论如何能用这些时髦的名词和选址这个其实不那么时髦的事情结合在一起。
在美国提到选址的地理数据分析,估计大多数企业已不觉得是什么新鲜事,那些深化到职业分层的人群数据,要拿到手也并不难。
然而,在中国,地理数据分析却一直处于瓶颈状态。一方面是地理信息的获取难度高。作为分析建模的基础,没有靠谱的数据,实属巧妇之无米之炊。另一方面是建模的难度大。海量的初始数据存在精确度问题,没有相关的经验,很难把大数据驱动起来。机缘巧合,我们在中国受一家受此困扰多年的国际顶级零售商委托,创新的实践了一次利用机器学习来选址的工作,所以对这个话题有着自己的见解。
对于零售企业,一切对地理数据的分析,都要回归到企业所要服务的“人”身上。而人的画像应该如何描绘?传统零售企业的方法是靠问卷调查,街头派发,有偿回答。但这样的方式导致的结果往往是:问卷的样本人群大多是“有闲而无钱”的人群。随着互联网数据越来越丰富,还需要完全依靠那样传统的问卷方式吗?我们能怎样打破局面?
古人曰,物物以理相连。一个咖啡厅开在小区的周围,必然因为这里的居民离不开他,他也依靠小区的居民生存和扩大规模,这我们称之为地物人之间“性感”的吸引力。应用在选址上,我们想到的解决方案是打通POI(信息点),用每个交通小区附近的店铺特征来推测居住人群特征。
附近有多少家咖啡厅?对应着怎样消费力的人群?这些人群中有多少是零售商的目标群体?如何把地物特征与人群特征联系起来?
这些是我们方案设计重点耕耘的工作。而这种分析方法,是传统地理信息系统所缺的。移动互联时代,网络上保存的信息上千万种,数据分析的发展空间大大提高。囿于其分析原理,传统的模型只能加入少量的指标。而我们使用机器学习曾经同时分析两百多个指标,完成多指标和它们之间复杂关系的分析,做到了传统方法无法达到的事情,不仅有量的提高,还有质的飞跃。
在帮助这家大型零售商进行选址的过程中,我们使用了机器学习预测模型,聪明的算法机制处理了十一个城市,数千万POI地理位置数据。人口、交通、房价、消费等等,在系统屏幕上一一闪现计算。
除了从大量数据中得出现实情况的规律,我们运用随机森林模型还能进行未知数据的预测。通过早期大量数据的训练,我们找到了最优“方程”(广义概念)。这样便能基于已有数据(自变量),计算出零售商感兴趣的预测值,如客群规模、潜在销量等。
我们首先从区域潜力评估入手,得出城市发展方向的趋势判断,在零售商给出优势区域里几个选址方案后,我们再提供具体店址评估报告辅助选址决策。经过长期的研究和模型训练,我们对地理数据的机器学习流程和自动化方案有了深刻的体会,在分析速度和精度上已达到行业内顶尖水平。
在项目进程中,合作的零售商也发现了一些让人惊喜的结果:很多之前靠经验积累,不明所以的判断,也在模型中一一得以验证。当然我们的分析也提供了之前无法洞察的大量信息。
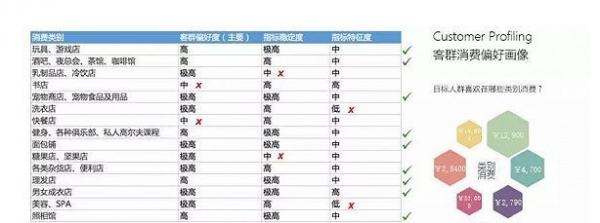
学习模型-客群消费偏好
目前我们正努力实现标签化地理区域,当企业有相关需求时,只需告诉我们需求和判断因子权重,就可以快速导出分析报告和结果。再下一步我们还考虑做成人工智能系统提供SaaS服务,用户输入数据,选择模型,便能快速到处辅助决策的结论报告。
然而,是否可以放心地说,AI在选址优化的工作中已经彻底打通关节,无所不能了吗?我的回答是:且慢。
首先,一个门店是否成功,除了周边的消费者特性,还取决于地产本身的质量,比如是否方便进入,门头是否足够醒目,房东可以提供的面积和租金,以及自身人员管理水平等。根据我的经验,这些因素在中国要占到6成。
机器学习所训练的,都是那些可以统一获取,没有主观因素的变量。而大量含有主观因素的变量的采集过程,都是人为筛选的,再智能的机器,也无法预测一个新的地点的可租面积,无法预测门头是否从四面八方都可以看见,人工智能无能为力。
其次,选址里面一个非常重要的故事是如何避免姐妹门店之间的相互蚕食,特别是连锁加盟型企业,面对加盟商,如果保证每家店的利益,避免法律诉讼。也许有人会说,我在模型里加入姐妹门店的距离,不就行了?以下面的地图为例,这个门店的消费者明显来自于高速公路的西北面,很少有人从东南过来。假如只考虑距离,而不知道消费者的分布,则很难告诉零售商,假如新增加一个门店这个区域里,开在哪里,不会蚕食现有门店的销售额。
这种情况,人工智能依然无法做出判断,因为几乎没有什么可以拿来学习,就算通过历史销售数据找出某些有可能出现蚕食的门店配对,学习的结论对于新的门店,依然毫无意义。这里就是体现出手机GPS定位数据的重要性了,但和AI无关,我们按下不表。
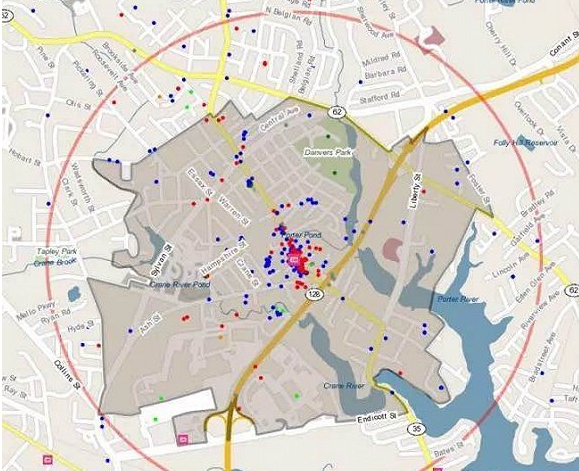
通过手机GPS数据和地理围栏Geofence技术获取的门店客源分布
总结一下:机器学习,对于选址里的主观变量,样本不足,无法用于预测等陷阱无法做到全智能。就算是机器学习本身,对于数据的选择也很有讲究。比如我们学习的门店,是在已经成熟的社区,而我们要预测的新址,却是在新区,那么模型很可能会给出误差。
这时就有必要拿出社区未成熟时的POI数据进行学习,寻找当时的规律。这一点其实是普适的:对于任何怀揣着机器学习/人工智能梦想就进入一个全新领域,却没有自身完善的数据积累的公司,都是前途叵测。
总体而言,机器学习/人工智能对零售选址带来的革新,是积极的。特别在中国,零售从线下轰轰烈烈地走到线上,又从线上回归到全渠道发展服务客户的商业本质。所以线下的需求肯定还会重启,特别是社区零售/连锁餐饮/便利店,开店的需求在持续增长。
特别是中国,在地理数据不开放,数据质量不高,数据层次不多的情况下,我们已经看到新方法可以有效地梳理出一些线索,完成从0到1的变化,这种质变比起AI在美国的模型仅仅是改进,是个飞跃。对于选址专家来说,这一代技术进步,为他们提供了一个智能慧眼,辅助着他们处理数据,寻找规律。
无论是像IBM这样的咨询服务商可以集成到自己零售解决方案,和Watson沃森的结合,还是像CBRE,JLL这样的房地产代理行,可以集成到自己的租户管理服务中,还是直接为零售企业的房地产部门做使用,AI技术都提供了多种可能。选址终归是一个艺术和科学的结合,结合丰富的市场经验和多方位的方法,这个为“新零售“选址的工作一定会更加高效。

















