








在8月12日,埃隆·马斯克旗下旨在研究通用人工智能解决方案的公司OpenAI,所训练的一款人工智能算法在著名的电子竞技游戏Dota2国际邀请赛The International中,参与了1V1比赛环节,并压倒性的击败了顶级电子竞技选手Dendi。
在alphago击败了柯洁以后,Deepmind多次公开表达了希望准备要去尝试挑战星际争霸等电子竞技项目,目前Deepmind确实也联合暴雪公司在开展这项尝试。因为相比围棋这种完全信息静态博弈游戏(即双方都能获得局面的所有信息,下棋异步),电子竞技游戏具备非完全信息属性(双方只掌握视野里的部分信息),而且竞技过程是实时动态进行的。其规则和特征复杂度远超围棋,因此对人工智能的局面评估、决策能力要求显著更高。另外,相比围棋这种高度抽象的游戏(只有落子一个动作),电子竞技游戏性质上更类似人类现实世界对抗/战争的简化模拟,涉及了大量资源调配、部队构成选择、扩张策略、攻防对抗等复杂但具有现实意义的博弈,如能在电子竞技对抗中取得划时代的里程碑,则代表了人工智能迈向通用化又进了一大步。
这就是为何Deepmind、OpenAI等顶尖人工智能公司都不约而同希望挑战电子竞技的根本原因,但大家没想到的是,人工智能这么快就在电子竞技界取得了成功。
由于目前OpenAI尚未公布其Dota2人工智能的设计细节,接下来我们通过分析和推测,力图揭秘其背后的奥秘所在。
背景知识:Dota 2游戏规则
Dota 2是一款类似于大众熟知的王者荣耀式的5V5竞技游戏,每边分别由5位玩家选择一名英雄角色,目标以为守护己方远古遗迹并摧毁敌方远古遗迹,通过提升等级、赚取金钱、购买装备和击杀对方英雄等诸多竞技手段。
这次OpenAI选择了挑战较为简单的1V1挑战,即OpenAI仅控制1名英雄,和顶级电子竞技选手Dendi操纵的1名英雄进行对抗。
比赛中,采取dota 2“一塔两杀”的规则,即双方玩家只允许出现在中路,任意一方摧毁对方中路首个防御塔,或者击杀对方英雄两次则取得胜利。游戏中,每隔30秒双方会获得一波电脑控制的较弱部队进入前线互相攻击,玩家杀死这些小兵可以获得金币,金币用于购买装备物品以强化英雄能力,同时消灭对方部队可获取到经验,经验获取到一定程度则可提升英雄等级,使得英雄能力更强,并获得技能点升级新的技能。同时双方各自还有一个初期威力强大的防御塔在身后,因此双方一般的对抗策略是尽量控制兵线在靠近己方防御塔的地方,同时努力杀死对方小兵(正补)并防止对手这样做(反补),获取经验和金币后升级技能,并试图通过攻击和技能击杀对方或摧毁对方防御塔。
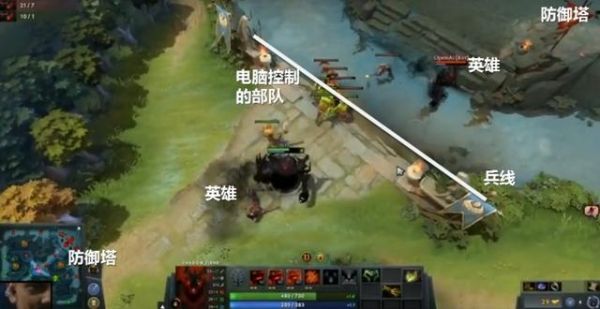
OpenAI的决策空间
上述是dota 2 1v1竞技的简单介绍,以供不了解dota 2的读者有个初步印象,接下来我们来分析一下在dota 2 1v1竞技中的决策空间及决策连续性这两个问题,这是与alphago完全不一样的存在,也是人工智能+电子竞技有趣的地方。
决策空间
相比围棋只有一个落子动作(选择一个空位下子),dota 2 1v1中的决策空间相对非常复杂,玩家每分每秒需要在以下的动作中做出决策:

当然,上述只是列举出了比较重要的战术动作,在实际竞技过程中还有大量的如取消攻击后摇、放风筝、控符、技能组合等高级动作。
决策连续性
围棋是一个典型的异步竞技游戏,选手在做出每一个决策前具有充分的决策时间,是典型的马尔科夫过程,但dota 2是一款实时竞技游戏,选手需要动态做出实时决策,这点是dota 2和围棋的另外一个不同。
那么OpenAI是怎么解决连续决策问题的?目前OpenAI尚未公布他们dota人工智能的细节。在这个问题上,OpenAI很有可能是通过考虑人类选手的决策效率,将决策过程离散化。Dota 2顶级选手的APM(action per minute,每分钟做出的动作)可达到200以上,众所周知人来大脑的反应速度是有极限的,一般顶级电竞选手在反应速度上都有异于常人的天赋,如果按比赛中观测到的APM来算,人类的极限可能在1秒钟做出4到5个动作决策,因此OpenAI如果每隔0.2秒做出一个动作决策的话,就能有超越人类的表现。
因此我这部分的猜测是,OpenAI很可能选择了200ms以内的某个值,在决策效率(更快的反应速度)和决策深度中取得了平衡,将dota 2 1v1比赛转变为类似围棋的马尔科夫决策过程。
OpenAI算法猜测:先验知识+增强学习
目前OpenAI对他们dota人工智能算法的细节披露相当有限,只是初步表示了他们并未使用任何模仿学习(Imitation Learning)或者类似于alphago的树搜索技术,纯粹使用了self-play即俗称 “左右互搏”的增强学习(reinforcement learning)方式训练。模仿学习是一种有监督的机器学习方法,如alphago最初的落子器就是通过围棋对战平台KGS获得的人类选手围棋对弈棋局训练出来的。而OpenAI并没有使用这种方法,可能主要原因还是较难获得dota 2 1v1的大量对局数据,由于dota 2中有100多个英雄角色可选择,每个英雄的属性和技能均不一样,意味着要对每个英雄做优化训练,如OpenAI在本次The International赛事中,只会使用一名英雄角色Shadow Field(影魔),从人类对局中获得海量(如10万局以上)高水平Shadow Field的1v1对局录像数据其实并不容易。
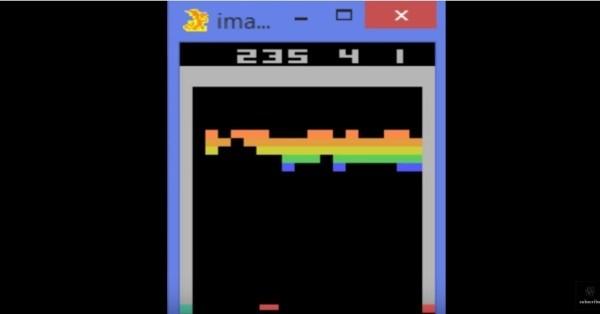
使用增强学习去令机器学会玩一款游戏,我们不禁马上联想起谷歌DeepMind使用RL学习来玩打砖块的经典案例。DeepMind模型仅使用像素作为输入,没有任何先验知识来辅助AI进行学习,算法Agent通过和环境S的交互,一开始选择随机动作A(向左还是向右移动滑板,动多少),并得到游戏分数的变化作为奖励,然后Agent继续如此玩下去,游戏结束后Agent得到最后游戏总分R,按照这种方式不断让Agent玩N局游戏,可以得到了一系列训练样本(S,A,R),通过训练一个神经网络去预测在状态S下,做动作A可能最后得到R,这样接下来Agent不再随机做出决策A,而是根据这个函数去玩,经过不断的迭代,Agent将逐渐掌握玩打砖块的诀窍,全程不需要人工制定任何的脚本规则。
但是,在dota 2之中,或许很难采取类似学习打砖块那样从随机行动开始的“大智若愚”方式去做增强学习,因为对于打砖块而言,每次动作A对于得分R的影响都是明确可量化的,但在dota 2中,这将会是一个非常长的链条。如以基本动作“补刀”为例:
补刀即对方小兵濒死时,控制英雄做出最后一击杀死小兵获得金钱,不是己方英雄亲自杀死小兵不会获得金钱。如果从随机行动开始,即AI胡乱攻击随机的目标,Agent要联系起补刀行为和最终胜利之间的关联是很困难的:补刀行为——小兵死亡——获得额外金钱——用金钱购买正确的物品——正确的物品增强英雄能力——提升获胜概率,完全不借助外界先验知识,仅通过模拟两个Agent“左右互搏”,从随机动作开始去做增强学习,其收敛速度会异常的慢,很可能哪怕模拟几百万局都不见得能学会“补刀”这个基本动作,但补刀仅仅是dota这个游戏入门的开始。
然而,根据OpenAI宣称,他们仅仅用了两周就完成了算法的训练,或许这里基本可以肯定,OpenAI使用了外界先验知识。
实际上,Dota 2游戏的开发商VALVE有一个dota 2机器人脚本框架,这个脚本框架下的机器人会熟练做出各种dota的基本动作,如补刀、释放技能、拦兵、追杀、按照脚本购买物品等,部分如补刀等依靠反应速度的动作可以展现得非常难缠。只不过机器人动作的执行非常机械,主要由于预设脚本的设定难以应对信息万变的实际竞技,使得机器人总体水平根本无法接近一般玩家,更别说跟职业顶级玩家相比了。
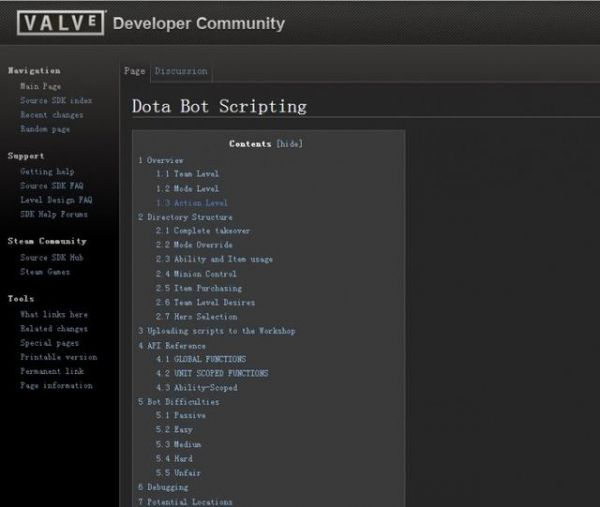
脚本机器人的优势是战术动作的执行,如上述增强学习很难马上学会的“补刀”动作脚本机器人天生就会,属于先验知识,而且可以凭借无反应时间和对目标血量和攻击力的精确计算做得非常完美,缺点在于行动决策弱智。这样如果祭出“组合拳”,使用脚本机器人执行基本战术动作,通过增强学习训练的神经网络负责进行决策,就像《射雕英雄传》中,武功高强但双目失明的梅超风骑在郭靖身上,长短互补一举击败众多高手那样,岂不完美?
我想OpenAI很可能也确实是这样做的,首先优化脚本机器人,将原子化的战术动作A的脚本做得尽善尽美,充分发挥机器的微操优势;同时通过增强学习训练一个神经网络,计算目前局势S下(包括场面小兵和双方英雄的状态和站位、技能CD和魔法值情况等),执行那个战术动作A得到的预期最终reward高,即A=P(Si),并且在较短的离散空间内,比如200ms不断进行决策并通过脚本执行动作A,最终使得OpenAI在大局观和微操上都取得尽善尽美。当然,由于OpenAI自身还没公布算法细节,上述方法只是一个最有可能的猜测,通过先验知识+增强学习获得一个单挑能力很强的Solo智能。
如果这个猜测正确的话,那么OpenAI在dota 2中通过1v1方式击败顶级职业选手这事情,远远没有alphago此前取得的成就来得困难。因为OpenAI在本次比赛中的表现,充其量等于训练了一个类似alphago落子器那样的应用而已。
而真正的挑战,在于Dota 2的5V5对抗中。
展望
目前,OpenAI通过增强学习,训练出了一个单挑solo能力非常强悍的算法,但是不得不说这个算法离Dota 2的5V5对抗中取胜还有非常大的距离。
在Dota 2的5V5对抗中,每方的5名玩家需要在英雄类型的合理搭配上、进攻策略上(如是速攻还是拖后期)、资源分配上(游戏中获得的金币根据局面购买何种物品)、局部战术等诸多因素上均保持顺畅沟通、并紧密配合才能取得对抗的胜利,每场比赛通常要大约进行30分钟以上,其过程的随机性非常强。
因此可见,OpenAI要在5v5中取得对人类的胜利,远远不是用1v1算法控制5个角色这么简单,5个在区域战场上单挑无敌的勇夫,并不意味着最终的胜利,接下来OpenAI的任务,就是让他们不要成为彼此“猪一样的队友”,而团队合作、对局面的宏观决策才是真正具有挑战意义的地方,同时也是人工智能从alphago这种机械性很强的专用智能,逐渐迈向通用智能的尝试。而OpenAI团队目前已经表示,他们正在准备向dota 2 5v5中全面击败强人类玩家战队的目标进发,并计划在明年接受这个挑战。























