









大数据文摘出品
编译:栾红叶、stats熊、蒋宝尚
最近深度学习技术实现方面取得的突破表明,顶级算法和复杂的结构可以将类人的能力传授给执行特定任务的机器。但我们也会发现,大量的训练数据对深度学习模型的成功起着至关重要的作用。就拿Resnet来说,这种图像分类结构在2015年的ILSVRC分类竞赛中获得了第一名,比先前的技术水平提高了约50%。

图1:近年来ILSVRC的顶级模型表现
Resnet不仅具有非常复杂艰深的结构,而且还有足够多的数据。不同的算法其性能可能是相同的,这个问题已经在工业界和学术界得到了很好的证实。
但需要注意的是,大数据应该是有意义的信息,而不是杂乱无章的,这样,模型才能从中学习。这也是谷歌、Facebook、亚马逊、Twitter、百度等公司在人工智能研究和产品开发领域占据主导地位的主要原因之一。
虽然与深度学习相比,传统的机器学习会需要更少的数据,但即使是大规模的数据量,也会以类似的方式影响模型性能。下图清楚地描述了传统机器学习和深度学习模型的性能如何随着数据规模的提高而提高。

图2:数据量与模型性能的函数关系
为什么我们需要机器学习?

图3:弹丸运动公式
让我们用一个例子来回答这个问题。假设我们有一个速度为v,按一定角度θ投掷出去的球,我们想要算出球能抛多远。根据高中物理知识,我们知道球做一个抛物线运动,我们可以使用图中所示的公式算出距离。
上述公式可被视为任务的模型或表示,公式中涉及的各种术语可被视为重要特征,即v、θ和g(重力加速度)。在上述模型下,我们的特征很少,我们可以很好地理解它们对我们任务的影响。因此,我们能够提出一个好的数学模型。让我们考虑一下另一种情况:我们希望在2018年12月30日预测苹果公司的股价。在这个任务中,我们无法完全了解各种因素是如何影响股票价格的。
在缺乏真实模型的情况下,我们利用历史股价和标普500指数、其他股票价格、市场情绪等多种特征,利用机器学习算法来找出它们潜在的关系。这就是一个例子,即在某些情况下,人类很难掌握大量特征之间的复杂关系,但是机器可以通过大规模的数据轻松地捕捉到它。
另一个同样复杂的任务是:将电子邮件标记为垃圾邮件。作为一个人,我们可能要想许多规则和启式的方法,但它们很难编写、维护。而另一方面,机器学习算法可以很容易地获得这些关系,还可以做得更好,并且更容易维护和扩展。既然我们不需要清晰地制定这些规则,而数据可以帮助我们获得这些关系,可以说机器学习已经彻底改变了不同的领域和行业。
大数据集是怎样帮助构建更好的机器学习模型的?
在我们开始讨论大规模数据是如何提高模型性能之前,我们需要了解偏差(Bias)和方差(Variance)。
偏差:让我们来看这样一个数据集:它的因变量和自变量之间是二次方关系。然而,我们不知道他们真实的关系,只能称它们近似为线性关系。在这种情况下,我们将会发现我们的预测与实际数据之间的明显的差异。观测值和预测值之间的这种差异称为偏差。这种模型,我们会说它功能小,欠拟合。
方差:在同一个例子中,如果我们将关系近似为三次方或任何更高阶,就会出现一个高方差的情况。方差能够反映训练集与测试集的性能差异。高方差的主要问题是:模型能很好地拟合训练数据,但在训练外数据集上表现得不好。这是验证确认测试集在模型构建过程中非常重要的一个主要原因。

图4:偏差 vs方差
我们通常希望将偏差和方差最小化。即建立一个模型,它不仅能很好地适用训练数据,而且能很好地概括测试/验证数据。实现这一点有很多方法,但使用更多数据进行训练是实现这一点的最佳途径之一。我们可以通过下图了解这一点:

图5:大数据产生了更好的泛化
假设我们有一个类似于正弦分布的数据。图(5a)描述了多个模型在拟合数据点方面同样良好。这些模型中有很多都过拟合,并且在整个数据集上产出不是很好。当我们增加数据时,从图(5b)可以看出可以容纳数据的模型数量减少。随着我们进一步增加数据点的数量,我们成功地捕获了数据的真实分布,如图(5C)所示。这个例子帮助我们清楚地了解数据数量是如何帮助模型揭示真实关系的。接下来,我们将尝试了解一些机器学习算法的这种现象,并找出模型参数是如何受到数据大小影响的。
线性回归:在线性回归中,我们假设预测变量(特征)和因变量(目标)之间存在线性关系,关系式如下:
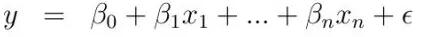
其中y是因变量,x(i)是自变量。β(i)为真实系数,ϵ为模型未解释的误差。对于单变量情况,基于观测数据的预测系数如下:
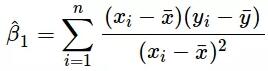
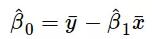
上述公式给出了斜率和截距的估测点,但这些估值总是存在一些不确定性,这些不确定性可由方差方程量化:
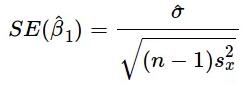
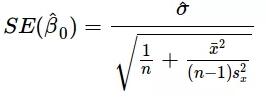
因此,随着数据数量的增加,分母会变大,就是我们估测点的方差变小。因此,我们的模型对潜在关系会更加自信,并能给出稳定的系数估计。通过以下代码,我们可以看到上述现象的实际作用:
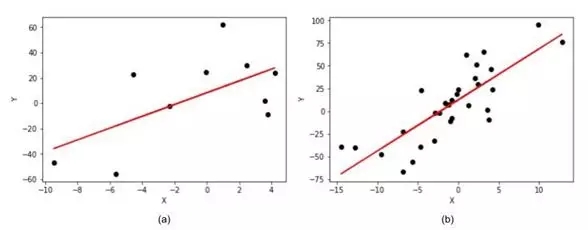
图6:在线性回归中增加数据量对估测点位置估测的提升
我们模拟了一个线性回归模型,其斜率(b)=5,截距(a)=10。从图6(a)(数据量小)到图6(b)(数据量大),我们建立了一个衰退模型,此时我们可以清楚地看到斜率和截距之间的区别。在图6(a)中,模型的斜率为4.65,截距为8.2,而图6(b)中模型的斜率为5.1,截距为10.2相比,可以明显看出,图6(b)更接近真实值。
k近邻(k-NN):k-NN是一种用于回归和分类里最简单但功能强大的算法。k-NN不需要任何特定的训练阶段,顾名思义,预测是基于k-最近邻到测试点。由于k-NN是非参数模型,模型性能取决于数据的分布。在下面的例子中,我们正在研究iris数据集,以了解数据点的数量如何影响k-NN表现。为了更好表现结果,我们只考虑了这组数据的四个特性中的两个:萼片长度和萼片宽度。

图7:KNN中预测类随数据大小的变化
后面的实验中我们随机从分类1中选取一个点作为试验数据(用红色星星表示),同时假设k=3并用多数投票方式来预测试验数据的分类。图7(a)是用了少量数据做的试验,我们发现这个模型把试验点错误分在分类2中。当数据点越来越多,模型会把数据点正确预测到分类1中。从上面图中我们可以知道,KNN与数据质量成正相关,数据越多可以让模型更一致、更精确。
决策树算法:与线性回归和KNN类似,也受数据数量的影响。

图8:根据数据的大小形成不同的树状结构
决策树也是一种非参数模型,它试图好地拟合数据的底层分布。拆分是对特性值执行的,目的是在子级创建不同的类。由于模型试图好地拟合可用的训练数据,因此数据的数量直接决定了分割级别和最终类。从上面的图中我们可以清楚的看到,数据集的大小对分割点和最终的类预测有很大的影响。更多的数据有助于找到最佳分割点,避免过度拟合。
如何解决数据量少的问题?
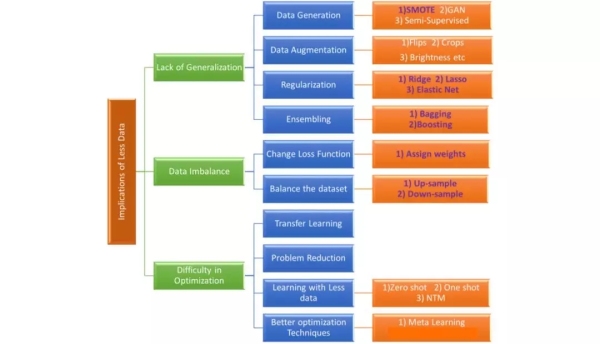
图9:数据量少的基本含义和解决它的可能方法和技术
上图试图捕捉处理小数据集时所面临的核心问题,以及解决这些问题的可能方法和技术。在本部分中,我们将只关注传统机器学习中使用的技术。
改变损失函数:对于分类问题,我们经常使用交叉熵损失,很少使用平均绝对误差或平均平方误差来训练和优化我们的模型。在数据不平衡的情况下,由于模型对最终损失值的影响较大,使得模型更加偏向于多数类,使得我们的模型变得不那么有用。
在这种情况下,我们可以对不同类对应的损失增加权重,以平衡这种数据偏差。例如,如果我们有两个按比例4:1计算数据的类,我们可以将比例1:4的权重应用到损失函数计算中,使数据平衡。这种技术可以帮助我们轻松地缓解不平衡数据的问题,并改进跨不同类的模型泛化。我们可以很容易地找到R和Python中的库,它们可以帮助在损失计算和优化过程中为类分配权重。Scikit-learn有一个方便的实用函数来计算基于类频率的权重:
我们可以用class_weight=‘balanced’来代替上面的计算量,并且与class_weights计算结果一样。我们同样可以依据我们的需求来定义分类权重。
异常/变更检测:在欺诈或机器故障等高度不平衡的数据集的情况下,是否可以将这些例子视为异常值得思考。如果给定的问题满足异常判据,我们可以使用OneClassSVM、聚类方法或高斯异常检测方法等模型。这些技术要求我们改变思维方式,将次要类视为异常类,这可能帮助我们找到分离和分类的新方法。变化检测类似于异常检测,只是我们寻找的是变化或差异,而不是异常。这些可能是根据使用模式或银行事务观察到的用户行为的变化。
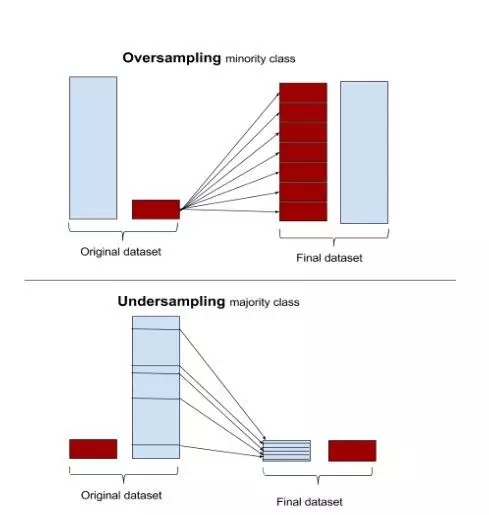
图10:过采和欠采样的情况
上采样还是下采样:由于不平衡的数据本质上是以不同的权重惩罚多数类,所以解决这个问题的一个方法是使数据平衡。这可以通过增加少数类的频率或通过随机或集群抽样技术减少多数类的频率来实现。过度抽样与欠抽样以及随机抽样与集群抽样的选择取决于业务上下文和数据大小。一般来说,当总体数据大小较小时,上采样是首选的,而当我们有大量数据时,下采样是有用的。类似地,随机抽样和聚集抽样是由数据分布的好坏决定的。
生成合成数据:尽管上采样或下采样有助于使数据平衡,但是重复的数据增加了过度拟合的机会。解决此问题的另一种方法是在少数类数据的帮助下生成合成数据。合成少数过采样技术(SMOTE)和改进过采样技术是产生合成数据的两种技术。简单地说,合成少数过采样技术接受少数类数据点并创建新的数据点,这些数据点位于由直线连接的任意两个最近的数据点之间。为此,该算法计算特征空间中两个数据点之间的距离,将距离乘以0到1之间的一个随机数,并将新数据点放在距离计算所用数据点之一的新距离上。注意,用于数据生成的最近邻的数量也是一个超参数,可以根据需要进行更改。
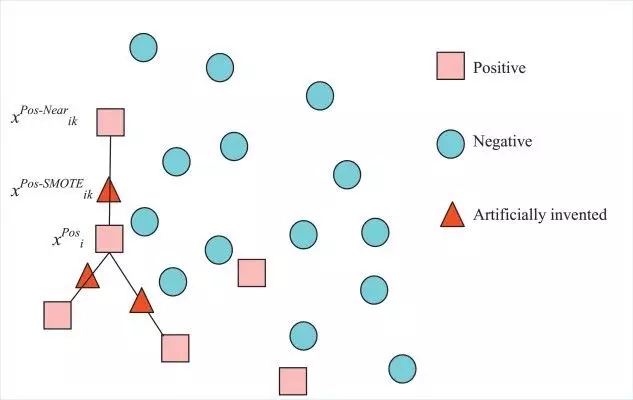
图11:基于K=3,合成少数过采样技术过程
M-SMOTE是一个改进版的SMOTE,它考虑了数据中少数分类的底层分布。该算法将少数类的样本分为安全/安全样本、边界样本和潜在噪声样本三大类。这是通过计算少数类样本与训练数据样本之间的距离来实现的。与SMOTE不同的是,该算法从k个最近邻中随机选择一个数据点作为安全样本,从边界样本中选择最近邻,对潜在噪声不做任何处理。
集成技术:聚合多个弱学习者/不同模型在处理不平衡的数据集时显示出了很好的效果。装袋和增压技术在各种各样的问题上都显示出了很好的效果,应该与上面讨论的方法一起探索,以获得更好的效果。但是为了更详细地了解各种集成技术以及如何将它们用于不平衡的数据,请参考下面的博客。
https://www.analyticsvidhya.com/blog/2017/03/imbalanced-classification-problem/
总结
在这段中,我们看到数据的大小可能会体现出泛化、数据不平衡以及难以达到全局最优等问题。我们已经介绍了一些最常用的技术来解决传统机器学习算法中的这些问题。根据手头的业务问题,上述一种或多种技术可以作为一个很好的起点。
【凡本网注明来源非中国IDC圈的作品,均转载自其它媒体,目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。】























