对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益大化,例如电商网站,网站推荐系统期望能实时根据顾客的点击行为分析其购买意愿,做到精准营销。
实时计算指针对只读(Read Only)数据进行即时数据的获取和计算,也可以成为在线计算,在线计算的实时级别分为三类:Real-Time(msec/sec级)、Near Real-Time(min/hours)以及Batch(days)。 在批处理方面,MapReduce(MR)已经证明其为最有效的工具,随着MR的开源实现hadoop为代表的大数据分析技术的普及,其在大处理方面的能力已经得到认可,但是它更适用于对集群上大数据的批处理,并不适用于实时处理大规模流数据。为了满足实时性的要求,基于数据仓库所构建的流计算和实时性计算框架也不断涌现,相关围绕MR的实时性优化技术也蓬勃发展,比较代表性的系统Google Dremel、Twitter Storm以及Yahoo S4等。
大数据的应用类型主要分为:批处理(Batch Processing)和流处理(Stream Processing)两方面。批处理是先存储后处理(Store-Then-Process),流处理是直接处理(Straight-Through-Processing),为提高商业智能的反映时间,目前广泛所采取的大数据处理框架,例如MR和Dryad所面向的主要是大规模数据分析,以批处理计算为主,其实时性需求得不到满足。常用的应用有在线推荐、网页点击分析、传感网络、交通分析以及金融中的高频交易,对实时分析处理(Real Time Analytic Processing, RTAP)的需求越来显著,网易公司作为国内大的门户网站之一,实时性也是公司目前互联网产品所应具备的重要属性。
网易大数据Spark技术应用Spark技术代表未来数据处理的新方向,Spark是UC Berkeley AMP lab开源的类Hadoop MapReduce的通用并行计算框架,Spark基于MapReduce实现分布式计算,拥有Hadoop MapReduce具有的优点。不同于MapReduce的是,Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
在网易大数据平台中,数据存储在HDFS之后,提供Hive的数据仓库计算和查询,要提高数据处理的性能并达到实时级别,网易公司采用的是Impala和Shark结合的混合实时技术。Cloudera Impala是基于Hadoop的实时检索引擎开源项目,其效率比Hive提高3-90倍,其本质是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。Shark是基于Spark的SQL实现,Shark可以比 Hive 快40倍(其论文所描述), 如果执行机器学习程序,可以快 25倍,并完全和Hive兼容。
图1和图2分别测试的计算能力和实时查询性能经过初步测试,在网易的实时计算平台,在大数据实时查询系统中,Impala在数据处理方面的速度可以相比HIVE达到3倍到30倍的加速比,Shark可以相比HIVE达到 1.5到15倍的加速比,相比较Impala和Shark引擎,通常Impala会比Shark快一倍,这里可能会引出思考,既然Impala实时性如此好,为何还需要Shark呢?
在设计大数据平台的时候,我们发现Impala性能不错,但是其对旧Hive的数据不兼容,因为目前的大数据应用中很多都是Hive的组织方式,而Shark可以完全兼容旧的数据,因此在目前的数据结构中必须采用混合的数据处理模式。Hive和Impala会协同存在一段时间, Hive主要为Predefined Queries,并主要处理批处理相关作业,而Impala则处理交互的查询(AD-HOC Queries),使得大数据系统既支持OLTP,也支持OLAP,以达到实时分析处理(Real Time Analytic Processing, RTAP)的水平。
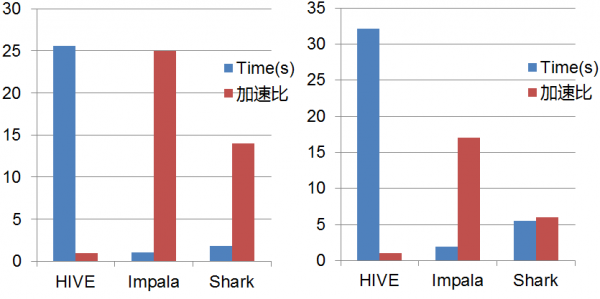
图1 网易大数据平台性能测试(Count/Sum/Avg操作)
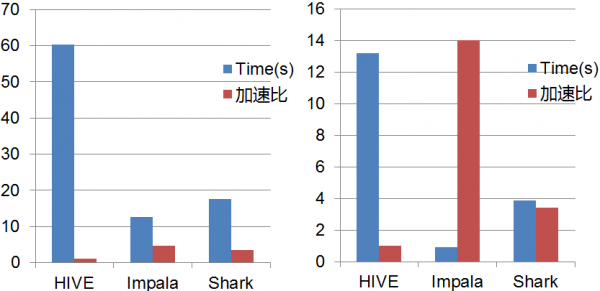
图2网易大数据平台性能测试(Join/Ad-hoc查询操作)
总结如果要评价2012到2013年度IT业界热词,非“大数据”一词莫属。ROI(Return On Investment)投资回报率已经演化为Return On Information,信息的回报率成为互联网公司的一个重要指标,如果所掌握的海量数据都是一堆“垃圾”,没有金矿去挖掘,那大数据也无从谈起,而提高ROI的一个重要属性就是实时性,提高数据的反应时间需要技术做支撑和保障,网易作为中国顶尖的互联网公司之一,在大数据方面也是最早的先行者,特别实时计算技术方面,公司很早就开始采用最新的技术来提供服务,例如Impala和Shark等,不难发现,网易的大数据系统可以灵活的选择计算实时引擎,总体上系统在实时处理方面的能力可以提升2到15倍,这对于提升公司的生产效率有显著成效,在后续的工作中期望可以进一步提升实时级别,目前只能做到秒级,能否达到毫秒级甚至微秒级别是将来的一个研发方向,总之对于海量数据计算、实时性方面有强烈需求的公司应用落地Spark是很好的选择。
参考资料
[1] Storm Distributed and fault-tolerant real time computation
[2] Leonardo Neumeyer, Bruce Robbins, Anish Nair, Anand Kesari. S4: Distributed Stream Computing Platform. 2010 IEEE International Conference on Data Mining Workshops (ICDMW)。
[3] Cloudera Impala https://github.com/cloudera/impala Reynold S. Xin, Josh Rosen, et al. Shark: SQL and rich analytics at scale. SIGMOD Conference 2013.