通常人们认为Spark的性能和速度全面优于MapReduce,但最新的对决显示MapReduce在某些方面也有胜场,而且数据规模越大优势越大。
Apache Spark是当今最火爆的大数据处理框架。通常人们认为Spark的性能和速度全面优于MapReduce,且更加容易使用,而且Spark已经拥有一个庞大的用户和贡献者社区,这意味着Spark更加符合下一代低延迟、实时处理、迭代计算的大数据应用的要求,大 有取代MapReduce的趋势。
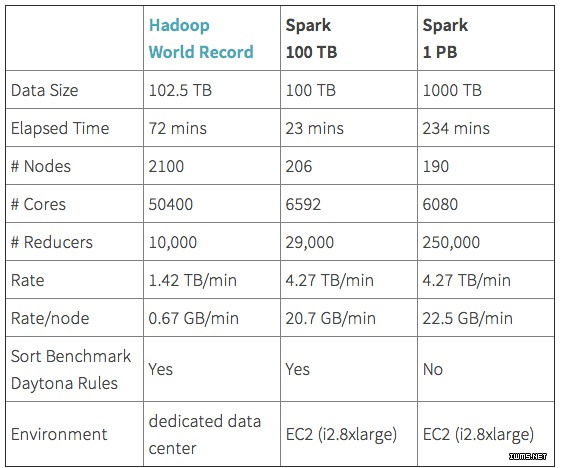
关于Spark和Mapreduce的性能PK已经在业界进行多次,不少人认为Spark仅仅是在内存计算环境比Mapreduce表现出色,但也有公司认为Spark全面压倒Mapreduce,例如2014年Spark商业化公司Databrick在磁盘环境给Spark做了GraySort跑分测试(下图),显示Spark的磁盘性能也同样彪悍。
那么,Spark真的是全面超越MapReduce了吗?
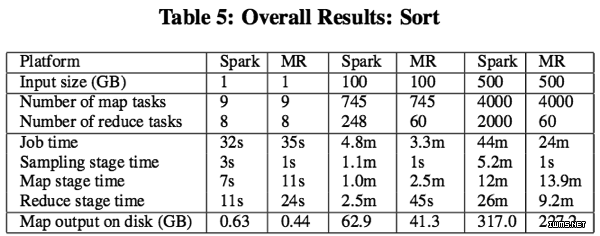
近日,IBM中国研究中心发布的一篇 论文 中的比测试显示,在Word Count、K-means和PageRank三类大数据处理任务中,Spark比MapReduce分别快2.5倍、5倍和5倍。这得益于的RDD缓存减少了CPU和磁盘开销。
但是在排序任务(Sort)方面,MapReduce的执行速度是Spark的两倍(两者的速度差异随着数据集规模的增加逐渐拉大,数据集越大,MapReduce的优势越明显,上图),因为MapReduce混编数据的执行模型比Spark的效率高很多。