








一、简介
TDSort是TDBank系统的一个模块,它从Tube中消费对应的Topic的数据,然后根据业务配置的数据结构信息,以及数据的目的地,将数据实时落地TDW、HBase和DB等数据存储系统中。
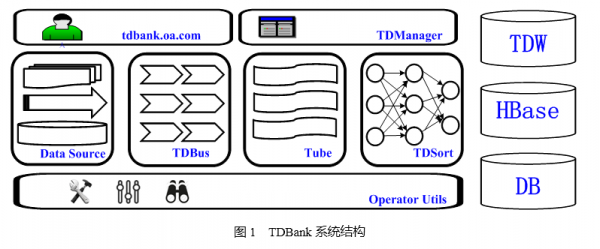
图1列出了TDbank系统的各个模块,目前TDBank支持的数据源有文本文件、MySql Binlog、DB全量读取和TCP/UDP消息。
TDBus是TDBank的接入层,它对公司所有的业务开放服务,按需自由对接。
Tube是TDBank的消息中心,它是TDBank参考Kafka的架构设计的一种高吞吐、低延时的消息中间件。
TDManager是TDBank的业务配置管理模块。
TDSort是TDBank中唯一解析数据的环节,它根据用户配置解析数据,然后将数据写入对应的目的地。
在TDBank系统中,使用“业务ID-接口名-数据时间”三个维度来定位一条数据所属于的数据单元。其中业务ID和接口名对应为TDW某个库中的一个数据表,而数据时间对应于TDW的数据分区。TDSort就是将数据按照用户的配置和本身的属性,将其放入对应的数据单元。
二、结构框图
TDSort是运行在Storm上的一个应用。Storm是Twitter开源的一个实时计算系统,Storm本身是分布式的,具有好的容错性和很高的性能。TDSort从Tube订阅数据进行处理;使用Zookeeper存储TDSort相关的配置,利用Zookeeper的watch通知机制实现对Strom的Worker的业务层管理。然后将对应数据单元的数据写入目的地,将其统计信息写入DB.如下图所示。
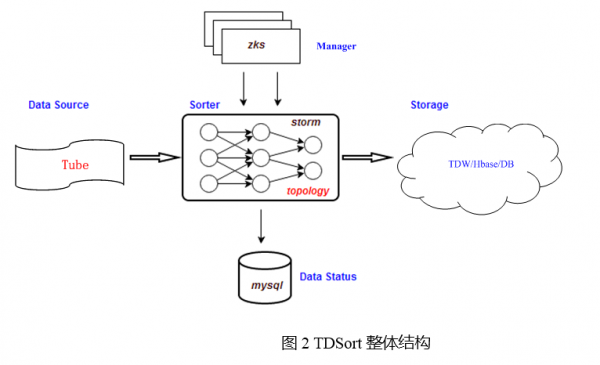
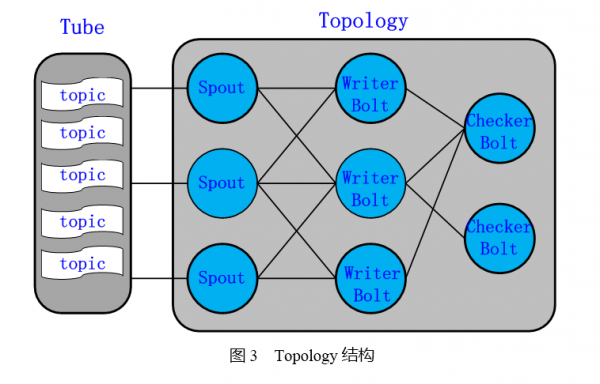
TDSort的结构由Spout带两级Bolt的结构组成,Spout后面的是WriterBolt,最后面是CheckerBolt,具体结构如下图所示。Topology的各个阶段之间是采用的FieldsGroup方式,用于做GroupBy的信息是业务ID、接口名、数据时间。
三、模块分解介绍
3.1 Spout结构
Spout按照业务的配置,订阅对应Topic的数据,然后是按照用户配置的数据协议解析数据。Topic是Tube中数据组织的逻辑概念,对应于一个业务的数据。目前TDSort支持的的数据协议格式有KV数据、文本数据、二进制的数据等。并且TDSort的数据是以插件的形式存在的,当需要支持新的数据格式时,开发和使用都非常方便。Spout按照数据所属的数据单元将它发送给对应的WriterBolt进行数据落地。
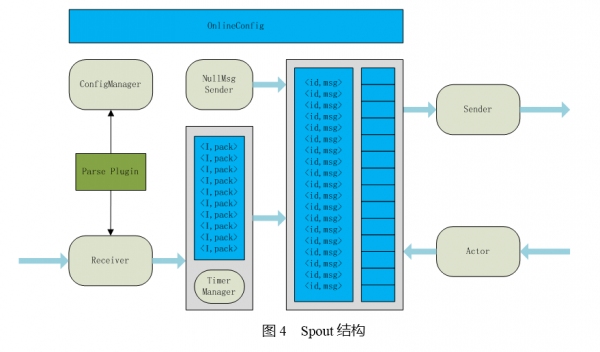
上图中的Receiver用于从Tube中接受对应需要处理的数据。一个表示一个数据单元。TimerManger数据单元的数据进行打包并且压缩,当数据包达到一定大小或者数据超时的情况下,将数据发送,然后以的形式放入待确认Map.之所以需要进行打包,是为了提升网卡的吞吐率,TDSort是以吞吐优先的数据处理系统。待确认Map和Strom本身的Acker机制实现了数据可靠传输(不出现数据丢失和数据重复)和流控。
TDSort的流量控制是结合Fail-Fast与Token-Bucket来设计的。在TDSort中,待确认Map是存放令牌的Bucket,不过在TDSort中,Token不是按照某个设定速率生成的,而是由后端的处理速度决定。后端每ack一条数据, Spout根据被ack数据的Msg-id将它从Map里面剔除,这样就等同于在Bucket中放入一个Token.而当Map中积压的Msg数量超过给定的阈值时,Spout会暂停Receiver.后端在感知自己处于BUSY状态时,可以调用Storm的fail接口主动通知Spout,然后Spout会降低Receiver的数据接受速度,当Spout频繁收到fail消息时,Spout也会暂停Receiver.在Token-Bucket和Fail-Fast的双重作用下,能大程度的匹配Spout和WriterBolt的处理速度,使得系统不会出现雪崩。
TDSort依靠Strom的Ack机制能够实现数据的可靠传输, 每一个Spout发送给Bolt的消息如果不被ack,Spout会重传这个消息,这样就能保证消息不出现丢失。但是Storm的重传机制有一个超时时间(topology.meesage.timeout.secs),如果在指定的时间内不被ack,Spout也会重传这个消息。这里我们将这个值为Worker的超时时间的两倍, Strom集群是同机房部署的情况下,然后Bolt是采用Fail-Fast的处理模式,这样就能保证消息被可靠传输,但是不会出现重复传输。
其中ConfigManager和OnlineConfig用于业务配置同步和管理通知。NullMsgSender用于触发空对账文件生成。空对账文件用标识对应的数据单元没有数据的情况。对于HBase和DataBase这样的以记录为单位的存储系统, Sender就直接写入对应的目的地中。
3.2 Bolt结构
WriterBolt接收到Spout发送的数据后,按照它所属的数据单元写入本地文件,当文件达到设定的阈值后就上传到HDFS,用于入库。
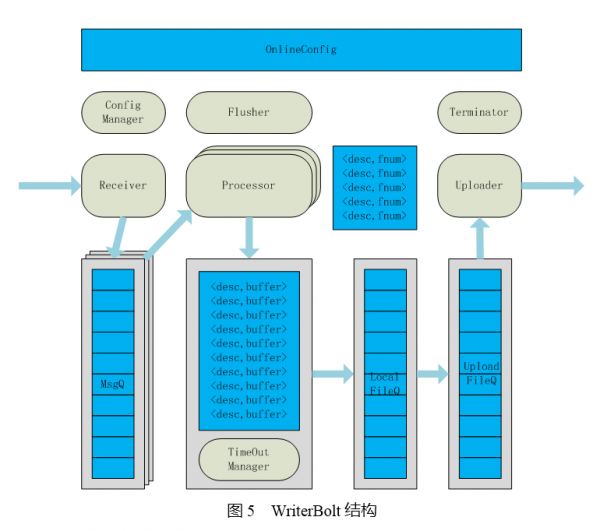
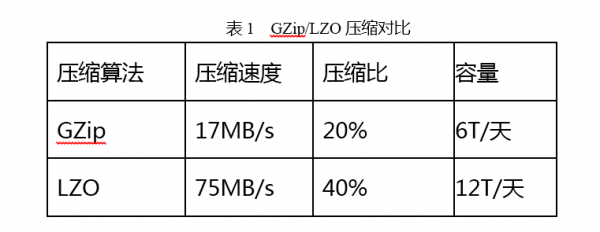
Receiver接收从Spout发送过来的Msg,Processor按照Msg所属的数据单元将数据放入TimeOutManager中进行打包,然后将满包或超时的数据由Flusher写入本地文件系统。这里的数据打包的作用是减少磁盘寻道的次数,以降低磁盘的压力。最后,达到设定文件大小的数据由Uploader采用LZO压缩后写入HDFS.这里使用LZO是在cpu计算资源与网络IO之间平衡的结果(TDW不支持Snappy压缩,故不做讨论)。GZip是一种常见的压缩效果非常好的压缩算法,但是它的压缩速度不快。下表是TDSort测试的两种压缩算法的对比结果。在测试中发现,同样的数据量使用GZip压缩,集群的CPU负载整体上升50%,而使用LZO只上升10%.而使用GZip会使得集群的CPU很快到达瓶颈;而使用LZO则是网卡先到达瓶颈,此时集群CPU的使用率为90%.不压缩的情况下,单机每天可以处理大约8T数据,对比下表,GZip相比于不压缩,系统容量还低一点,所以TDSort最后选择了LZO算法。Terminator的作用是将Uploader上传的文件名称,数据记录数信息传给CheckerBolt.
为什么Spout解析出来的数据不直接落地,而是传给WriterBolt来处理。主要是为了减少小文件的产生,减少分拣产生的文件数,降低对HDFS的元数据和TDSort磁盘带来的压力。因为各个Spout的工作是对等,假设系统中有20个Spout,而T1数据单元有20MB数据,如果在Spout直接落地,会导致系统生成20个1MB的文件,那样HDFS的元数据就会增长20倍,对于整个系统来说磁盘寻道次数也翻了20倍,磁盘寻道的时间是毫秒级别的,它会为TDSort的磁盘带来巨大的压力。但是这样做也带来了两个问题,数据倾斜和网络开销翻倍。对于数据倾斜,我们的处理策略是加入切分因子,让Spout根据切分因子把数据发给多个Bolt处理,切分因子是运维按需配置。对于网络消耗的问题,我们将数据使用Snappy压缩后在用网络传输,来减小网络的压力。
3.3 CheckerBolt
CheckerBolt功能比较简单,就是根据WriterBolt收到的数据单元的数据文件名信息和数据记录数生成对账文件,然后在DB中写入对应的数据单元的统计信息。增加CheckerBolt的原因是为了实现数据单元的信息汇总。
四、总结
目前TDSort每天分拣万亿的数据入库到TDW、HBase和DB中,在系统出现异常的时候,可以通过重新设置Tube的Offset实现回溯。在整个TDSort的实现过程中有很多后台系统设计的共性问题。TDSort中所有的线程间与进程之间的通信都采用消息队列的模式,实现简单方便。在各种硬件资源的平衡的问题,Spout到WriterBolt的网络传输是网络IO与磁盘IO之间资源平的结果。而LZO算法的选择则是CPU资源与IO资源之间平衡的结果。























