








中国IDC圈5月19日报道,生命科学的大数据还处在比较初始的阶段,否则国家也不会现在才开始提出精准医学这样的概念。所谓精准医学想通过大数据模型准确预测预防,个性化的给每个人提供健康解决方案的项目。
机能强大的人脑
作为生命科学来说首先是要认识自己,这是刚刚去世的纳什,诺贝尔奖获得者,这个图片讲的是他到五角大楼里面去帮五角大楼破解苏联密码,结果他看着满墙数字跳动的时候很自然的圈定几个数字,把苏联计划进入美国的经纬度所谓的密码数字圈了出来,帮助五角大楼瓦解苏联的进攻。
从这个例子我们应该看到其实我们每个人的大脑都是非常强的大数据处理机器,接下去我大概讲一下我们大脑为什么会这么强,大脑的处理能力有多强。我们大脑只有140亿个脑细胞,从出生到死亡基本是不会变的。为什么从出生到死亡我们的知识是不一样的,就是因为脑细胞会建立突出的连接,这个人越聪明突出的连接就越复杂。
二是大脑的能耗特别低,只有20瓦,大家在拼命思考的时候脑子会发热,不会像CPU一样热的过高烧起来。
我们做一项对比,我们把大脑跟英特尔刚出的e7的CPU对比,这样一个CPU大概有56亿个,能耗要105瓦,我们大脑在能耗上面跟CPU对比处理能力和能耗比,比现在的机器强很多。
从一生过程来看,人的一生大概能存储100PB的存储量,是美国600个国家图书馆的量,加起来是140PB,正常人是能存储140个PB。这是什么概念?比如说因特网上所有的音乐加起来就是10个P左右。大脑的集散能力也特别强,一天能处理86G的信息,如果把处理能力换算成超算的计算速度,大脑的计算速度在3.5EFlops,现在超级计算机远远没有达到。
现在最快的天河2号连续五年拿到了世界超算排名第一的计算机研究,可见大脑的计算能力相当可以。另外一个例子,我们眼睛的分辨率大概是5.7千万像素,人的眼睛到这么高的分辨率,但人的大脑还能实时处理这些图片,以每秒25帧的数据处理,大脑的数据能力是非常强的。
我们先认识一下自己的大脑还是非常强大的,在某个专业领域跟计算机领域比还是有不足,但整体比较计算机是很难超越人的大脑的。
人体大数据
我们说到大数据有两层含义,有的大数据是数量上面的,有的大数据是数据大小上面。我们再来认识一下我们自己身体其它部位的大数据的情况,人类的基因是30亿个碱基,整个身体大概是100万亿个细胞,同时在我们的肠道里有一千万亿个细菌,肠道是我们的外环境,不要以为是我们的内环境,我们的生活是内外相互作用的结果。
如果把跟健康所有相关的数据汇总在一些,看看有哪些类型,要使遗传信息有功能的话,把基因组信息翻译成RA,再翻译成蛋白 ,同时基因组还跟环境有一定的相互作用,这个相互作用是通过这里的表观组学来实现的。我们体内还有很多小分子,我们这里说的叫Metabolome,Microbiome是我刚才提到的一千万亿数量的细菌,这些遗传因素跟我们的环境有相互关系。
同时现在可穿戴的设备特别流行,日常生活中的心电、血糖、心率都可以通过可穿戴设备记录下来,这也跟日常健康有很大的关系。跟神奇的是,大家不要以为社交网络跟身体没关系,其实社交网络跟我们内在基因也是有一定的关系的,但随着研究的发展这种关系可能会越来越强。
环境对人的影响
接下去把每个类型展开,首先讲环境,每个人的健康一出生50%健康的情况就已经决定了,由你内在遗传的物质决定,DNA决定了你接下去的生活是什么样的情况,另外50%就是我们刚才说的外在的环境,会对我们的健康生活产生一定的影响,这个占50%的样子。

这个是表观组学,这个主要反应了环境跟内在DNA相互作用的情况。在我们三十亿的碱基里面只有2%的碱基是表达基因的,另外98%在科学里面叫做垃圾基因,不管是2%的基因还是98%的垃圾基因里面都有一些“短创”,这个短创对基因组的功能起到调控作用。科学研究表明,在三十亿碱基里面我们发现了28890个,这个在有功能的2%的部分里大概有56%的基因功能是受它控制的。
要把基因组环境和人的关系建立起来的话,其实要在不同的环境里测表观组的情况,一个人需要2个T的数据来存储。
再就是宏基因组,我们有1TB细菌在我们体内,这些细菌大概有两公斤,这些细菌对我们生活起到非常大的影响或者决定性作用。
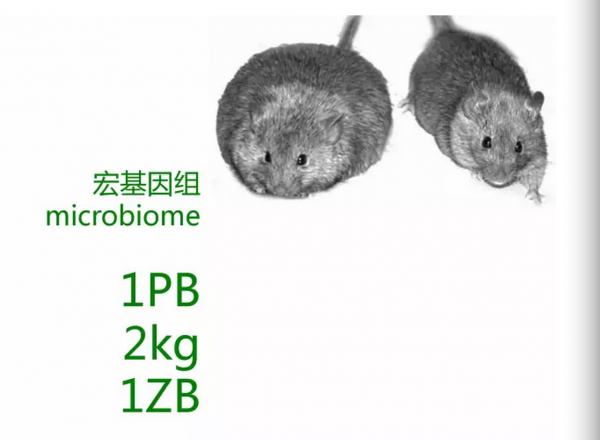
这是两只老鼠,这是中科院上海生命科学研究院赵力群教授的研究成果,他养的两只老鼠,一只养的特别胖,一只特别瘦,他做了一个实验,把特别胖的老鼠的粪便做成培养液喂给瘦的老鼠,结果瘦的老鼠变得非常胖,反过来也是。表明人的肠道里的细菌跟人的饮食习惯有特别大的关系。
一个人喜欢吃什么,其实不是你喜欢吃什么,是你肠道里面的细菌喜欢吃什么。这是一个很好的产业,能够把这个问题真正解决清楚,这是一个非常大的产业。
前段时间华大基因刚发现了糖尿病跟宏基因组之间的关系,还跟人的血压,甚至跟癌症还有关系,能产生抗癌的基因,细菌能产生抗癌的因素帮助人类抵抗癌症。
大家到医院检查的时候都会查血常规,但是大家很少接触到比较专的一些,比如说氨基酸、维他命和激素,氨基酸、维他命和激素和人的情绪、健康状况有很大关系,你还是要时不时看一下人体里的小分子,就是分子量在1000以下的这些分子在你体内分布的情况。
以前我们很乐观的认为人的基因组里人有25000个基因组,后来随着研究发现没有那么多,只有19000个,这是很悲催的,水稻的基因有3000个,其实高等的生物有另外一种基因的产生或者进入了另外一个形态。如果我们要测一个人的基因组一般会测上三十遍,才能大概把一个人的基因组的情况摸清楚,三十遍这就需要100GB的数据,如果要测一百万人的话光数据就需要100TB。
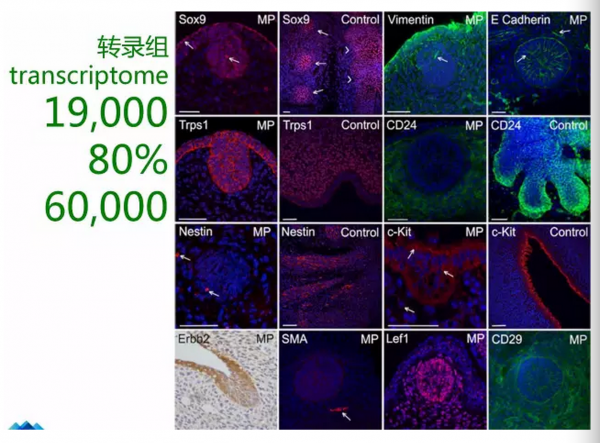
这是转录组,在19000个基因里80%的基因可能有多种形态,一段基因组转录出来以后有很多的酶切成不同的片段再连接起来,基因组有不同的方式,把这个形式算上去的话人大概有60000个基因,对于一个高等生物来说还算可以。
从转录组到真正行使功能的时候要放大成蛋白,从6000个转录组RNA里提取多少蛋白,大概是二十到两百万之间,可见蛋白的形态比RNA更复杂,因为有很多不同的折叠形式,不同的折叠形式空间是不一样的,蛋白的数量就会显得特别多。
6788是中国人在蛋白基因组里承担的肝脏蛋白的项目情况,发现人的肝脏里面大概有6788个蛋白种类,而且这里面大概有一千种是新的。
刚才说到了这么多小分子,他们是怎么相互作用的,我们有这样一个小分子基因网络的数据库,记录了三千个物种基因相互作用的情况。这三千个物种里面基因的数量大概是1.2千万个基因,1.2千万个基因形成了相互作用的这种大概是28万。
这就记录了我们日常生活所有的习惯,比如说你吃米饭,米饭在你身体里怎么消化、怎么吸收,怎么转化成糖源,所有这个过程都是通过基因网络来描述的,我们现在也只有28万个网络,要比我们想象的少很多,当然这个数据库还是要不断地积累才能说清楚身体是怎么样的行使功能的。
基因造成的人群差异
我们再说一下人之间的差异,任何两个人之间如果没有基础关系的话,它的差异只有0.5,也就是说两个人之间大概有150兆左右的基因组序列是不一样的,但是如果我们只看上下两代之间的差异,这个差异就是60-100DNA序列多肽性的不一样,这也能解释说为什么相似度更高一点。
这些差异从日常相貌和行动行为就能看出来,日常生活中经常看到单眼皮、双眼皮,有些人的舌头是可以卷的,有些不能卷,还有秃顶,男士的秃顶很大程度上跟基因是有关系的,另外还有喝酒脸不脸红,这跟基因有很大关系,有些人喝一点点就脸红,有些人喝很多都不脸红。
我们再看一下人和其它物种,我们跟植物只有17%左右的基因组相似,跟我们很近的猩猩只有96%相似。
现在研究表明大的基因,一个细胞里面有670Gb组碱基对,就是人的两百多倍了,这个基因组还是很大。为什么我们很关心基因组的大小?
大家对这个基因组稍微了解的话知道我们从做基因组测序来说,要把一个基因组测完整其实是很不容易的,像人的基因组是把人的基因组切成大概一个KB这样的片段,一段段测完之后拼起来,我们现在看到人的基因组其实是1K左右的序列拼起来的。现在拼的人的基因组是3G,人的内存大概是500G,一台机器要有500G的内存才能把3个G的基因组拼起来,那要拼600多G的基因组需要什么计算机器呢?
这是一个很大的挑战,我们还是比较关心基因组的大小的。同时基因组里还有很多有趣的东西,AP+ALE 以后也很有趣,有时候测出来你不知道在哪里,没有证据表明一定要放在一个地方。
举个例子,如果要把世界上所有的DNA收集起来有多重,它大概有500亿吨的重量,如果要把它装在集装箱里其实需要十亿个集装箱,把500亿吨的DNA处理一遍的话需要10的21次方超级计算机,这其实是一个天文数字,大家很难想象,如果我们要建这么大的模型应该怎么处理。
我们再来看看医学方面,我们到医院拍一张3D核磁共振体大概需要150兆的空间,如果是3D的CT,一个结果就是一个G,当然胸透的数据和X光透视的数据相对小一点。
我们做一个统计,如果把三甲院士抽选,在美国相对还行的医院做一个统计一年大概有3600万个病人到医院看病,这些病人每年在医院里产生的数据大概是600个TB,而且这些数据还特别复杂。
有照片的数据、有病例的数据,甚至有时间纬度的数据,这些数据还是挺复杂,80%的数据其实是非结构化的,每个医院里面的数据在每年以20%-40%的增长率增长,这个数据一点都不比基因组数据小,如果有刚才说的精准模型的话,它表明了你基因和外界环境相互作用的结果是什么,所以你一定要把这个参数考虑进去,这些数据也是整合到这个模型里做计算的。
我们大概能知道我们现在通过传感器,记录也好、监控也好身体上的这部分数据,比如身体的坐姿、消化情况、呼吸的情况,还有心脏监护,这些数据目前都有很好的监护,这些数据也是需要整合到精准医学的系统里面。
最后一个是社交/婚姻基因,美国的一个测试,找了一堆很好的朋友测他们的基因,发现好朋友之间1%之间的基因相像,但是古代有酒肉朋友和异性相吸这样的成语,有跟喝酒有关的基因,这个基因越强你可能越喜欢酗酒,酒肉朋友这个词就可以通过这个基因来体现,还有跟荷尔蒙、情感有关的。甚至有科学家发现婚姻也与基因有关系,这个基因越向下这两个人越倾向于在一起。
如果把所有数据整合起来,如果把一个人一生健康相关的数据整合一起需要多大,基因需要一个DB,转录组是0.7TB,表观组是2TB,宏观基因组是3TB。如果要做一百万人的数据大概需要10EB,像阿里,百度数据量级也差不多是这个级别了。但是做这样一个项目需要这么大的存储空间。
为什么要做精准医学
就是希望自己活的更长,理论上讲每个人如果生活的条件非常平稳、非常好的话,本身基因没有什么缺陷,每个人大概能活150岁,这是在理想条件下面。但实际情况并不是这样,有15%的家庭是有不孕不育的问题,在出生的婴儿里大概5.6%有出生缺陷,有出生缺陷的婴儿其实是活不了太长的,大概活到二十岁左右。
对于青年们来说还有很重要的疾病会影响他的健康状况,比如说代谢病、癌症、传染病,对于二十岁到五十岁之间的青年人这些疾病是他们主要疾病的威胁。对于中年人,他们的代谢病大概有30%的患病率,心血管疾病和癌症是中年人主要的生命杀手。老年人,心血管疾病的危害是特别大的,反而是癌症和老年病还好。
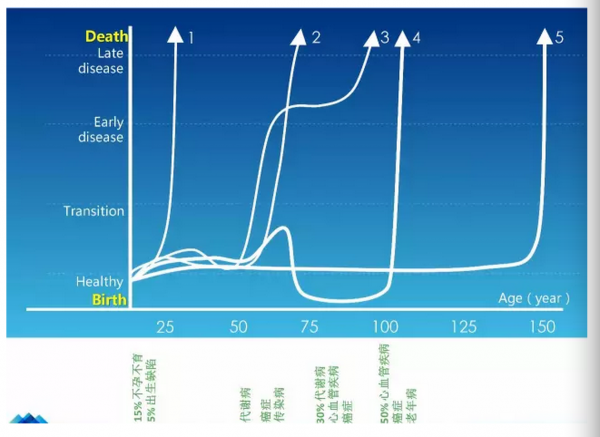
从这个曲线上看,1就代表了你出生的时候如果有很大缺陷的话肯定活不了太久,但是2和3恩都代表了现在大部分人的生活情况,你刚开始的时候很健康,到中老年的时候会发生各种各样的疾病的问题,有一些疾病可以治,有一些疾病治不了的立刻挂掉,如果能治一般也是苟延残喘维持一段时间,维持不了太久,到一定程度以后也就不行了。
比较理想的情况,我们能做到的可能是4,你出生的时候还是很健康的,一旦发现你的健康到不健康转移的过程的时候,如果我们有很好的预测的模型,我们其实是完全可以通过一系列的干预手段把自己的健康状况从不健康和转化的状态拉回来重新再往下走,就有一个很好的监控预防的体系。
在5.6%的出生缺陷了跟遗传有关的只占30%,但这30%也是很可观的,这些数字是我们中国大概一年有缺陷的人口的情况。现在大家经常听到猝死和癌症的增长,增长率都是很可怕的,癌症一年的增长率在30%到40%,在中国这个是特别严重的,五十几万猝死的人群里面大概有15%-25%跟你的DNA是有关的。
如果这些人能够提早的把自己的DNA或自己相关的基因检查一遍的话其实完全可以避免,因为一旦发现这些人有相关的基因突变的话就可以警告你自己,所以你不要做太剧烈的运动、不要熬夜,有一些生活的状况是可以调节完全避免,通过有效手段能够避免猝死的发生。
还有癌症,大部分的癌症像现在的乳腺癌10%-15%跟基因有关,所以女性同胞们确实是可以通过检测你相关的乳腺癌基因来提早预防乳腺癌或者卵巢癌的发生,还有直肠癌和肺癌,肺癌10%和你的基因有关。如果你真的把健康数据做一个记录的话,其实是可以通过日常生活调节很容易避免这些严重的后果。
还有我们说的罕见病,霍金是得了渐冻症,发病率千分之0.6到1。如果我们完全想建立这样一个健康的模型,我们的样板量要足够均匀、足够大,所以才能抽样到所有类型的数据,我们觉得在一百万的时候可能把常见的常见病或复杂的遗传疾病覆盖住,能很好的建立这样一个模型来预测和预防。
接下去给大家介绍几个商业化的大家可以体验的产品,最著名的是23andMe,现在已经积累了大概80万个DNA的序列,我自己也有23andMe的结果。以前我特别不喜欢吃香菜,有一次23andMe给我发了一个邮件说发现你基因里有这个问题,这个问题的基因是不喜欢吃香菜的,我就想这个还是很准确的。
23andMe另外一个很重要的例子,它是作这个领域大数变现的第一个公司,它跟罗氏(音)合作,罗氏用它清洗完的数据,给它一千万美金,如果合作的好罗氏好像还要给他们五千万美金。这是一个例子。
第二个例子是华大内部用的小的软件,希望把我们日常生活记录下来,以后可以跟你的基因组数据对一下,请私人医生也好、遗传咨询师也好,请他们帮你看一下这个东西,给你制定生活的规律性的方案。
在这个App上可以通过扫二维码获取,里面有可穿戴设备的整合,还有你的运动情况、日常隐私可以记录。华大做了一些检测,我们做了代谢组和基因的检测数据都可以在这个App里看到。这个App我们没有大的推广,也是在做一个实验性的东西,大家有兴趣可以下载,如果大家对自己的健康足够关心的话其实需要留心自己日常的生活的数据,这样你好知道自己今后会有什么样的状况。
第三个例子是陈钢他们公司做的,也是国内在这个领域里做的比较成功的商业化的例子。因为我本人比较喜欢运动,经常跑一个马拉松,但我发现跑到10公里的时候经常抽筋,我觉得这个事情特别奇怪,把我的基因数据导到他们的系统里看我的运动相关的基因是什么情况,结果发现有些道理,在我的结果里我的爆发力还行,在短程的速度能跑到每小时十公里,但是我的耐力特别差,我没法做到很长久的运动,可能大概能解释我跑步的情况。
另外一个我很得意的是恢复能力,跑马拉松的人要三四天才能恢复,我大概第二天就能跑、能跳,基因的结果相对来说还是有一定的辅助作用。还有饮食跟运动对减肥的影响,这也是比较有趣的。
我跟我老婆经常较劲,我发现我只要稍微一结实体重立刻减下来或者稍微加一点运动量就立刻减下来,我老婆就不行,基因还是反应了这样一些例子,大家有兴趣还是可以看一下,比如你喜欢运动可以去看一下你运动的情况什么样子,对大家的生活还是有些帮助的。
第四个例子是喝酒,现在大家应酬特别多,但大家对酒精和乙醇对身体的伤害都是不知道的,这是我们近期测试的一个小的应用,测出你大概喝酒的能力怎么样,还可以告诉你究竟对你的伤害是什么样的。
如果酒精对你的伤害不大的话无所谓,如果对你的伤害很大的话就应该注意不能够喝酒,特别是肝脏的损害,同时我觉得这个可以作为挡酒的理由,如果你喝酒能力差可以把这个拿出来,基因说明了这一点,可以作为挡酒的借口。
最后这个例子是在国外,它可以给你一个盒子,你把你擦皮肤的棉签寄过去,它就可以把你的菌群测一下,只能测厚壁菌、拟杆菌、变形菌这几种。
我们为什么要收集这些数据,是不是所有这些事情华大都可以做?不是的,我们其实还是要联合社会上所有的公司和个人,来建立一个完整的生态系统,这样我们才有可能收集到这么多的数据建一个健康的模型。大概把设想写了一下,希望把数据、信息和知识通过API的形式整合到不同的四个层次,让所有人在上面开发自己感兴趣的健康应用来指导大家的健康生活。























