








在本章中,我们将介绍如何使用深度学习来解决计算机视觉、语音识别、自然语言处理以及其他商业领域中的应用。首先我们将讨论在许多最重要的AI 应用中所需的大规模神经网络的实现。接着,我们将回顾深度学习已经成功应用的几个特定领域。

尽管深度学习的一个目标是设计能够处理各种任务的算法,然而截至目前深度学习的应用仍然需要一定程度的特化。例如,计算机视觉中的任务对每一个样本都需要处理大量的输入特征(像素),自然语言处理任务的每一个输入特征都需要对大量的可能值(词汇表中的词) 建模。
大规模深度学习
深度学习的基本思想基于联结主义:尽管机器学习模型中单个生物性的神经元或者说是单个特征不是智能的,但是大量的神经元或者特征作用在一起往往能够表现出智能。我们必须着重强调神经元数量必须很大这个事实。
相比20世纪80年代,如今神经网络的精度以及处理任务的复杂度都有一定提升,其中一个关键的因素就是网络规模的巨大提升。在过去的30年内,网络规模是以指数级的速度递增的。然而如今的人工神经网络的规模也仅仅和昆虫的神经系统差不多。由于规模的大小对于神经网络来说至关重要,因此深度学习需要高性能的硬件设施和软件实现。
快速的CPU实现
传统的神经网络是用单台机器的CPU 来训练的。如今,这种做法通常被视为是不可取的。现在,我们通常使用GPU 或者许多台机器的CPU 连接在一起进行计算。在使用这种昂贵配置之前,为论证CPU 无法承担神经网络所需的巨大计算量,研究者们付出了巨大的努力。
描述如何实现高效的数值CPU 代码已经超出了本书的讨论范围,但是我们在这里还是要强调通过设计一些特定的CPU 上的操作可以大大提升效率。例如,在2011 年,好的CPU 在训练神经网络时使用定点运算能够比浮点运算跑得更快。通过调整定点运算的实现方式,Vanhoucke et al. (2011) 获得了3 倍于一个强浮点运算系统的速度。因为各个新型CPU都有各自不同的特性,所以有时候采用浮点运算实现会更快。一条重要的准则就是,通过特殊设计的数值运算,我们可以获得巨大的回报。除了选择定点运算或者浮点运算以外,其他的策略还包括了如通过优化数据结构避免高速缓存缺失、使用向量指令等。机器学习的研究者们大多会忽略这些实现的细节,但是如果某种实现限制了模型的规模,那该模型的精度就要受到影响。
GPU实现
许多现代神经网络的实现基于图形处理器(Graphics Processing Unit, GPU)。图形处理器最初是为图形应用而开发的专用硬件组件。视频游戏系统的消费市场刺激了图形处理硬件的发展。GPU为视频游戏所设计的特性也可以使神经网络的计算受益。
大规模的分布式实现
在许多情况下,单个机器的计算资源是有限的。因此,我们希望把训练或者推断的任务分摊到多个机器上进行。
分布式的推断是容易实现的,因为每一个输入的样本都可以在单独的机器上运行。这也被称为数据并行(data parallelism)。
同样地,模型并行(model parallelism) 也是可行的,其中多个机器共同运行一个数据点,每一个机器负责模型的一个部分。对于推断和训练,这都是可行的。
在训练过程中,数据并行从某种程度上来说更加困难。对于随机梯度下降的单步来说,我们可以增加小批量的大小,但是从优化性能的角度来说,我们得到的回报通常并不会线性增长。使用多个机器并行地计算多个梯度下降步骤是一个更好的选择。不幸的是,梯度下降的标准定义完全是一个串行的过程:第t 步的梯度是第t ¡ 1 步所得参数的函数。
这个问题可以使用异步随机梯度下降(Asynchoronous Stochasitc Gradient Descent)(Bengio et al., 2001b; Recht et al., 2011) 解决。在这个方法中,几个处理器的核共用存有参数的内存。每一个核在无锁的情况下读取这些参数,并计算对应的梯度,然后在无锁状态下更新这些参数。由于一些核把其他的核所更新的参数覆盖了,因此这种方法减少了每一步梯度下降所获得的平均提升。但因为更新步数的速率增加,总体上还是加快了学习过程。Deanet al. (2012) 率先提出了多机器无锁的梯度下降方法,其中参数是由参数服务器(parameterserver) 管理而非存储在共用的内存中。分布式的异步梯度下降方法保留了训练深度神经网络的基本策略,并被工业界很多机器学习组所使用(Chilimbi et al., 2014; Wu et al., 2015)。学术界的深度学习研究者们通常无法负担那么大规模的分布式学习系统,但是一些研究仍关注于如何在校园环境中使用相对廉价的硬件系统构造分布式网络(Coates et al., 2013)。
模型压缩
在许多商业应用的机器学习模型中,一个时间和内存开销较小的推断算法比一个时间和内存开销较小的训练算法要更为重要。对于那些不需要个性化设计的应用来说,我们只需要一次性地训练模型,然后它就可以被成千上万的用户使用。在许多情况下,相比开发者,终端用户的可用资源往往更有限。例如,开发者们可以使用巨大的计算机集群训练一个语音识别的网络,然后将其部署到移动手机上。
减少推断所需开销的一个关键策略是模型压缩(model compression)(Bucilu·a et al., 2006)。模型压缩的基本思想是用一个更小的模型取代替原始耗时的模型,从而使得用来存储与评估所需的内存与运行时间更少。
当原始模型的规模很大,且我们需要防止过拟合时,模型压缩就可以起到作用。在许多情况下,拥有最小泛化误差的模型往往是多个独立训练而成的模型的集成。评估所有n 个集成成员的成本很高。有时候,当单个模型很大(例如,如果它使用Dropout 正则化) 时,其泛化能力也会很好。
这些巨大的模型能够学习到某个函数f(x),但选用的参数数量超过了任务所需的参数数量。只是因为训练样本数是有限的,所以模型的规模才变得必要。只要我们拟合了这个函数f(x),我们就可以通过将f 作用于随机采样点x 来生成有无穷多训练样本的训练集。然后,我们使用这些样本训练一个新的更小的模型,使其能够在这些点上拟合f(x)。为了更加充分地利用这个新的小模型的容量,好从类似于真实测试数据(之后将提供给模型) 的分布中采样x。这个过程可以通过损坏训练样本或者从原始训练数据训练的生成模型中采样完成。
此外,我们还可以仅在原始训练数据上训练一个更小的模型,但只是为了复制模型的其他特征,比如在不正确的类上的后验分布(Hinton et al., 2014, 2015)。
动态结构
一般来说,加速数据处理系统的一种策略是构造一个系统,这个系统用动态结构(dynamicstructure) 描述图中处理输入所需的计算过程。在给定一个输入的情况中,数据处理系统可以动态地决定运行神经网络系统的哪一部分。单个神经网络内部同样也存在动态结构,给定输入信息,决定特征(隐藏单元) 哪一部分用于计算。这种神经网络中的动态结构有时被称为条件计算(conditional computation)(Bengio, 2013; Bengio et al., 2013b)。由于模型结构许多部分可能只跟输入的一小部分有关,只计算那些需要的特征就可以起到加速的目的。
动态结构计算是一种基础的计算机科学方法,广泛应用于软件工程项目。应用于神经网络的最简单的动态结构基于决定神经网络(或者其他机器学习模型) 中的哪些子集需要应用于特定的输入。
深度网络的专用硬件实现
自从早期的神经网络研究以来,硬件设计者就已经致力于可以加速神经网络算法的训练和/或推断的专用硬件实现。读者可以查看早期的和更近的专用硬件深度网络的评论(Lindseyand Lindblad, 1994; Beiu et al., 2003; Misra and Saha, 2010)。
不同形式的专用硬件(Graf and Jackel, 1989; Mead and Ismail, 2012; Kim et al., 2009; Phamet al., 2012; Chen et al., 2014b,a) 的研究已经持续了好几十年,比如专用集成电路(application—speci¯c integrated circuit, ASIC) 的数字(基于数字的二进制表示)、模拟(Graf and Jackel,1989; Mead and Ismail, 2012)(基于以电压或电流表示连续值的物理实现) 和混合实现(组合数字和模拟组件)。近年来更灵活的现场可编程门阵列(¯eld programmable gated array, FPGA)实现(其中电路的具体细节可以在制造完成后写入芯片) 也得到了长足发展。
虽然CPU 和GPU 上的软件实现通常使用32 位或64 位的精度来表示浮点数,但是长期以来使用较低的精度在更短的时间内完成推断也是可行的(Holt and Baker, 1991; Holi andHwang, 1993; Presley and Haggard,1994; Simard and Graf, 1994; Wawrzynek et al., 1996; Savichet al., 2007)。这已成为近年来更迫切的问题,因为深度学习在工业产品中越来越受欢迎,并且由于更快的硬件产生的巨大影响已经通过GPU 的使用得到了证明。激励当前对深度网络专用硬件研究的另一个因素是单个CPU 或GPU 核心的进展速度已经减慢,并且最近计算速度的改进来自核心的并行化(无论CPU 还是GPU)。这与20 世纪90 年代的情况(上一个神经网络时代) 的不同之处在于,神经网络的硬件实现(从开始到芯片可用可能需要两年) 跟不上快速进展和价格低廉的通用CPU 的脚步。因此,在针对诸如手机等低功率设备开发新的硬件设计,并且想要用于深度学习的一般公众应用(例如,具有语音、计算机视觉或自然语言功能的设施) 时,研究专用硬件能够进一步推动其发展。
最近对基于反向传播神经网络的低精度实现的工作(Vanhoucke et al., 2011; Courbariauxet al., 2015; Gupta et al., 2015) 表明,8 位和16 位之间的精度足以满足使用或训练基于反向传播的深度神经网络的要求。显而易见的是,在训练期间需要比在推断时更高的精度,并且数字某些形式的动态定点表示能够减少每个数需要的存储空间。传统的定点数被限制在一个固定范围之内(其对应于浮点表示中的给定指数)。而动态定点表示在一组数字(例如一个层中的所有权重) 之间共享该范围。使用定点代替浮点表示并且每个数使用较少的比特能够减少执行乘法所需的硬件表面积、功率需求和计算时间。而乘法已经是使用或训练反向传播的现代深度网络中要求高的操作。
计算机视觉
长久以来,计算机视觉就是深度学习应用中几个最活跃的研究方向之一。因为视觉是一个对人类以及许多动物毫不费力,但对计算机却充满挑战的任务(Ballard et al., 1983)。深度学习中许多流行的标准基准任务包括对象识别和光学字符识别。
计算机视觉是一个非常广阔的发展领域,其中包括多种多样的处理图片的方式以及应用方向。计算机视觉的应用广泛:从复现人类视觉能力(比如识别人脸) 到创造全新的视觉能力。举个后者的例子,近期一个新的计算机视觉应用是从视频中可视物体的振动识别相应的声波(Davis et al., 2014)。大多数计算机视觉领域的深度学习研究未曾关注过这样一个奇异的应用,它扩展了图像的范围,而不是仅仅关注于人工智能中较小的核心目标|| 复制人类的能力。无论是报告图像中存在哪个物体,还是给图像中每个对象周围添加注释性的边框,或从图像中转录符号序列,或给图像中的每个像素标记它所属对象的标识,大多数计算机视觉中的深度学习往往用于对象识别或者某种形式的检测。由于生成模型已经是深度学习研究的指导原则,因此还有大量图像合成工作使用了深度模型。尽管图像合成(“无中生有”) 通常不包括在计算机视觉内,但是能够进行图像合成的模型通常用于图像恢复,即修复图像中的缺陷或从图像中移除对象这样的计算机视觉任务。
预处理
由于原始输入往往以深度学习架构难以表示的形式出现,许多应用领域需要复杂精细的预处理。计算机视觉通常只需要相对少的这种预处理。图像应该被标准化,从而使得它们的像素都在相同并且合理的范围内,比如[0; 1] 或者[¡1; 1]。将[0; 1] 中的图像与[0; 255] 中的图像混合,通常会导致失败。将图像格式化为具有相同的比例,严格上说是唯一一种必要的预处理。许多计算机视觉架构需要标准尺寸的图像,因此必须裁剪或缩放图像以适应该尺寸。然而,严格地说即使是这种重新调整比例的操作并不总是必要的。一些卷积模型接受可变大小的输入,并动态地调整它们的池化区域大小以保持输出大小恒定(Waibel et al., 1989)。其他卷积模型具有可变大小的输出,其尺寸随输入自动缩放,例如对图像中的每个像素进行去噪或标注的模型(Hadsell et al., 2007)。
数据集增强可以被看作一种只对训练集做预处理的方式。数据集增强是减少大多数计算机视觉模型泛化误差的一种极好方法。在测试时可用的一个相关想法是将同一输入的许多不同版本传给模型(例如,在稍微不同的位置处裁剪的相同图像),并且在模型的不同实例上决定模型的输出。后一个想法可以被理解为集成方法,并且有助于减少泛化误差。
其他种类的预处理需要同时应用于训练集和测试集,其目的是将每个样本置于更规范的形式,以便减少模型需要考虑的变化量。减少数据中的变化量既能够减少泛化误差,也能够减小拟合训练集所需模型的大小。更简单的任务可以通过更小的模型来解决,而更简单的解决方案泛化能力一般更好。这种类型的预处理通常被设计为去除输入数据中的某种可变性,这对于人工设计者来说是容易描述的,并且人工设计者能够保证不受到任务影响。当使用大型数据集和大型模型训练时,这种预处理通常是不必要的,并且好只是让模型学习哪些变化性应该保留。例如,用于分类ImageNet 的AlexNet 系统仅具有一个预处理步骤:对每个像素减去训练样本的平均值(Krizhevsky et al., 2012b)。
数据集增强
如第7.4 节中讲到的一样,我们很容易通过增加训练集的额外副本来增加训练集的大小,进而改进分类器的泛化能力。这些额外副本可以通过对原始图像进行一些变化来生成,但是并不改变其类别。对象识别这个分类任务特别适合于这种形式的数据集增强,因为类别信息对于许多变换是不变的,而我们可以简单地对输入应用诸多几何变换。如前所述,分类器可以受益于随机转换或者旋转,某些情况下输入的翻转可以增强数据集。在专门的计算机视觉应用中,存在很多更高级的用以增强数据集的变换。这些方案包括图像中颜色的随机扰动(Krizhevskyet al., 2012b),以及对输入的非线性几何变形(LeCun et al., 1998c)。
语音识别
语音识别任务是将一段包括了自然语言发音的声学信号投影到对应说话人的词序列上。令X = (x(1), x(2), …, x(T)) 表示语音的输入向量(传统做法以20ms 为一帧分割信号)。许多语音识别的系统通过特殊的手工设计方法预处理输入信号,从而提取特征,但是某些深度学习系统(Jaitly and Hinton, 2011) 直接从原始输入中学习特征。令y = (y1; y2,…, yN) 表示目标的输出序列(通常是一个词或者字符的序列)。自动语音识别(automatic speech recognition,ASR) 任务指的是构造一个函数f*ASR,使得它能够在给定声学序列X 的情况下计算最有可能的语言序列y:
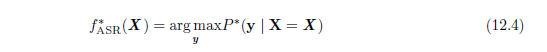
其中P*是给定输入值X 时对应目标y 的真实条件分布。
从20 世纪80 年代直到2009»2012 年,最先进的语音识别系统是隐马尔可夫模型(hiddenmarkov model, HMM) 和高斯混合模型(gaussian mixture model, GMM) 的结合。GMM 对声学特征和音素(phoneme) 之间的关系建模(Bahl et al., 1987),HMM 对音素序列建模。GMM-HMM 模型将语音信号视作由如下过程生成:首先,一个HMM 生成了一个音素的序列以及离散的子音素状态(比如每一个音素的开始、中间、结尾),然后GMM 把每一个离散的状态转化为一个简短的声音信号。尽管直到最近GMM-HMM 一直在ASR 中占据主导地位,语音识别仍然是神经网络所成功应用的第一个领域。从20 世纪80 年代末期到90 年代初期,大量语音识别系统使用了神经网络(Bourlard and Wellekens, 1989; Waibel et al., 1989; Robinsonand Fallside, 1991; Bengio et al., 1991, 1992; Konig et al., 1996)。当时,基于神经网络的ASR的表现和GMM-HMM 系统的表现差不多。比如说,Robinson and Fallside (1991) 在TIMIT数据集(Garofolo et al., 1993)(有39 个区分的音素) 上达到了26% 的音素错误率,这个结果优于或者说是可以与基于HMM 的结果相比。从那时起,TIMIT 成为音素识别的一个基准数据集,在语音识别中的作用就和MNIST 在对象识别中的作用差不多。然而,由于语音识别软件系统中复杂的工程因素以及在基于GMM-HMM 的系统中已经付出的巨大努力,工业界并没有迫切转向神经网络的需求。结果,直到21 世纪00 年代末期,学术界和工业界的研究者们更多的是用神经网络为GMM-HMM 系统学习一些额外的特征。
之后,随着更大更深的模型以及更大的数据集的出现,通过使用神经网络代替GMM 来实现将声学特征转化为音素(或者子音素状态) 的过程可以大大地提高识别的精度。从2009年开始,语音识别的研究者们将一种无监督学习的深度学习方法应用于语音识别。这种深度学习方法基于训练一个被称作是受限玻尔兹曼机的无向概率模型,从而对输入数据建模。受限玻尔兹曼机将会在第三部分中描述。为了完成语音识别任务,无监督的预训练被用来构造一个深度前馈网络,这个神经网络每一层都是通过训练受限玻尔兹曼机来初始化的。这些网络的输入是从一个固定规格的输入窗(以当前帧为中心) 的谱声学表示抽取,预测了当前帧所对应的HMM 状态的条件概率。训练一个这样的神经网络能够可以显著提高在TIMIT 数据集上的识别率(Mohamed et al., 2009,2012a),并将音素级别的错误率从大约26% 降到了20:7%。关于这个模型成功原因的详细分析可以参考Mohamed et al. (2012b)。对于基本的电话识别工作流程的一个扩展工作是添加说话人自适应相关特征(Mohamed et al., 2011) 的方法,这可以进一步地降低错误率。紧接着的工作则将结构从音素识别(TIMIT 所主要关注的)转向了大规模词汇语音识别(Dahl et al., 2012),这不仅包含了识别音素,还包括了识别大规模词汇的序列。语音识别上的深度网络从最初的使用受限玻尔兹曼机进行预训练发展到了使用诸如整流线性单元和Dropout 这样的技术(Zeiler et al., 2013; Dahl et al., 2013)。从那时开始,工业界的几个语音研究组开始寻求与学术圈的研究者之间的合作。Hinton et al. (2012a)描述了这些合作所带来的突破性进展,这些技术现在被广泛应用在产品中,比如移动手机端。
随后,当研究组使用了越来越大的带标签的数据集,加入了各种初始化、训练方法以及调试深度神经网络的结构之后,他们发现这种无监督的预训练方式是没有必要的,或者说不能带来任何显著的改进。
用语音识别中词错误率来衡量,在语音识别性能上的这些突破是史无前例的(大约30%的提高)。在这之前的长达十年左右的时间内,尽管数据集的规模是随时间增长的(见Deng and Yu (2014) 的图2.4),但基于GMM-HMM 的系统的传统技术已经停滞不前了。这也导致了语音识别领域快速地转向深度学习的研究。在大约两年的时间内,工业界大多数的语音识别产品都包含了深度神经网络,这种成功也激发了ASR 领域对深度学习算法和结构的新一波研究浪潮,并且影响至今。
其中的一个创新点是卷积网络的应用(Sainath et al., 2013)。卷积网络在时域与频域上复用了权重,改进了之前的仅在时域上使用重复权值的时延神经网络。这种新的二维卷积模型并不是将输入的频谱当作一个长的向量,而是当成一个图像,其中一个轴对应着时间,另一个轴对应的是谱分量的频率。
完全抛弃HMM 并转向研究端到端的深度学习语音识别系统是至今仍然活跃的另一个重要推动。这个领域第一个主要突破是Graves et al. (2013),他训练了一个深度的长短期记忆循环神经网络(见第10.10 节),使用了帧-音素排列的MAP 推断,就像LeCun et al. (1998c)以及CTC 框架(Graves et al., 2006; Graves, 2012) 中一样。一个深度循环神经网络(Graves et al., 2013) 每个时间步的各层都有状态变量,两种展开图的方式导致两种不同深度:一种是普通的根据层的堆叠衡量的深度,另一种是根据时间展开衡量的深度。这个工作把TIMIT 数据集上音素的错误率记录降到了新低17:7%。关于应用于其他领域的深度循环神经网络的变种可以参考Pascanu et al. (2014a); Chung et al. (2014)。
另一个端到端深度学习语音识别方向的最新方法是,让系统学习如何利用语音(phonetic)层级的信息“排列”声学(acoustic) 层级的信息(Chorowski et al., 2014; Lu et al., 2015)。
自然语言处理
自然语言处理(natural language processing,NLP) 是让计算机能够使用人类语言,例如英语或法语。为了让简单的程序能够高效明确地解析,计算机程序通常读取和发出特殊化的语言。而自然语言通常是模糊的,并且可能不遵循形式的描述。自然语言处理中的应用如机器翻译,学习者需要读取一种人类语言的句子,并用另一种人类语言发出等同的句子。许多NLP 应用程序基于语言模型,语言模型定义了关于自然语言中的字、字符或字节序列的概率分布。
与本章讨论的其他应用一样,非常通用的神经网络技术可以成功地应用于自然语言处理。然而,为了实现卓越的性能并扩展到大型应用程序,一些领域特定的策略也很重要。为了构建自然语言的有效模型,通常必须使用专门处理序列数据的技术。在很多情况下,我们将自然语言视为一系列词,而不是单个字符或字节序列。因为可能的词总数非常大,基于词的语言模型必须在极高维度和稀疏的离散空间上操作。为了使这种空间上的模型在计算和统计意义上都高效,研究者已经开发了几种策略。
n-gram
语言模型(language model) 定义了自然语言中标记序列的概率分布。根据模型的设计,标记可以是词、字符甚至是字节。标记总是离散的实体。最早成功的语言模型基于固定长度序列的标记模型,称为n-gram。一个n-gram 是一个包含n 个标记的序列。
神经语言模型
神经语言模型(neural language model, NLM) 是一类用来克服维数灾难的语言模型,它使用词的分布式表示对自然语言序列建模(Bengio et al., 2001b)。不同于基于类的n-gram 模型,神经语言模型在能够识别两个相似的词,并且不丧失将每个词编码为彼此不同的能力。神经语言模型共享一个词(及其上下文) 和其他类似词(和上下文之间) 的统计强度。模型为每个词学习的分布式表示,允许模型处理具有类似共同特征的词来实现这种共享。例如,如果词dog和词cat映射到具有许多属性的表示,则包含词cat的句子可以告知模型对包含词dog的句子做出预测,反之亦然。因为这样的属性很多,所以存在许多泛化的方式,可以将信息从每个训练语句传递到指数数量的语义相关语句。维数灾难需要模型泛化到指数多的句子(指数相对句子长度而言)。该模型通过将每个训练句子与指数数量的类似句子相关联克服这个问题。
高维输出
在许多自然语言应用中,通常希望我们的模型产生词(而不是字符) 作为输出的基本单位。对于大词汇表,由于词汇量很大,在词的选择上表示输出分布的计算成本可能非常高。在许多应用中,V 包含数十万词。表示这种分布的朴素方法是应用一个仿射变换,将隐藏表示转换到输出空间,然后应用softmax 函数。假设我们的词汇表V 大小为|V|。因为其输出维数为|V|,描述该仿射变换线性分量的权重矩阵非常大。这造成了表示该矩阵的高存储成本,以及与之相乘的高计算成本。因为softmax 要在所有|V| 输出之间归一化,所以在训练时以及测试时执行全矩阵乘法是必要的|| 我们不能仅计算与正确输出的权重向量的点积。因此,输出层的高计算成本在训练期间(计算似然性及其梯度) 和测试期间(计算所有或所选词的概率) 都有出现。对于专门的损失函数,可以有效地计算梯度(Vincent et al., 2015),但是应用于传统softmax 输出层的标准交叉熵损失时会出现许多困难。
结合n-gram 和神经语言模型
n-gram 模型相对神经网络的主要优点是n-gram 模型具有更高的模型容量(通过存储非常多的元组的频率),并且处理样本只需非常少的计算量(通过查找只匹配当前上下文的几个元组)。如果我们使用哈希表或树来访问计数,那么用于n-gram 的计算量几乎与容量无关。相比之下,将神经网络的参数数目加倍通常也大致加倍计算时间。当然,避免每次计算时使用所有参数的模型是一个例外。嵌入层每次只索引单个嵌入,所以我们可以增加词汇量,而不会增加每个样本的计算时间。一些其他模型,例如平铺卷积网络,可以在减少参数共享程度的同时添加参数以保持相同的计算量。然而,基于矩阵乘法的典型神经网络层需要与参数数量成比例的计算量。
因此,增加容量的一种简单方法是将两种方法结合,由神经语言模型和n-gram 语言模型组成集成(Bengio et al., 2001b, 2003)。
对于任何集成,如果集成成员产生独立的错误,这种技术可以减少测试误差。集成学习领域提供了许多方法来组合集成成员的预测,包括统一加权和在验证集上选择权重。Mikolovet al. (2011a) 扩展了集成,不是仅包括两个模型,而是包括大量模型。我们也可以将神经网络与大熵模型配对并联合训练(Mikolov et al., 2011b)。该方法可以被视为训练具有一组额外输入的神经网络,额外输入直接连接到输出并且不连接到模型的任何其他部分。额外输入是输入上下文中特定n-gram 是否存在的指示器,因此这些变量是非常高维且非常稀疏的。
模型容量的增加是巨大的(架构的新部分包含高达|sV |n 个参数),但是处理输入所需的额外计算量是很小的(因为额外输入非常稀疏)。
神经机器翻译
机器翻译以一种自然语言读取句子并产生等同含义的另一种语言的句子。机器翻译系统通常涉及许多组件。在高层次,一个组件通常会提出许多候选翻译。由于语言之间的差异,这些翻译中的许多翻译是不符合语法的。例如,许多语言在名词后放置形容词,因此直接翻译成英语时,它们会产生诸如“apple red”的短语。提议机制提出建议翻译的许多变体,理想情况下应包括“red apple”。翻译系统的第二个组成部分(语言模型) 评估提议的翻译,并可以评估“red apple”比“apple red”更好。
最早的机器翻译神经网络探索中已经纳入了编码器和解码器的想法(Allen 1987; Chris-man 1991; Forcada and ~Neco 1997),而翻译中神经网络的第一个大规模有竞争力的用途是通过神经语言模型升级翻译系统的语言模型(Schwenk et al., 2006; Schwenk, 2010)。之前,大多数机器翻译系统在该组件使用n-gram 模型。机器翻译中基于n-gram 的模型不仅包括传统的回退n-gram 模型(Jelinek and Mercer, 1980; Katz, 1987; Chen and Goodman, 1999),而且包括大熵语言模型(maximum entropy language models)(Berger et al., 1996),其中给定上下文中常见的词,a±ne-softmax 层预测下一个词。
关联阅读:























