








工业大数据的范畴。
工业大数据包括制造企业信息化数据、工业物联网数据,以及外部跨界数据。信息化数据包括了ERP中的客户订单、生产计划等信息 ,工业物联网数据主要是从生产设备上采集到的各种产质耗数据和智能产品上获得的运维数据,而外部跨界数据包括环境数据、市场数据和竞品数据等,而其中从机器设备上得到的数据比重将越来越大。
工业大数据的特征除了大数据的4V(数据量大、类型多、价值密度低、速度快)以外,还有专业性、关联性、和时序性特征。工业大数据应该注意特征背后的物理意义以及特征之间关联性的机理逻辑,互联网上的大数据可以只针对数据本身进行挖掘和关联,而不考虑数据本身的意义,挖掘到什么结果就是什么结果。工业大数据的挖掘必须要有明确的挖掘目标,针对应用的功能在此基础上逐步扩展挖掘的方向。
为什么大数据上云要轻量化?
制造企业在构建大数据分析系统时,除了采用传统的自建数据中心架构以外,还可以采用数据存储和分析构建在公有云平台,采用离线训练模型,结合边缘计算在生产现场利用实时数据和已经训练好的模型进行业务应用的两级架构。
两级架构的优点主要体现在以下四个方面:
1、降低存储成本:从设备传感器上采集的数据点往往是时序连续的过程量,随着采集频率的提高和周期延长,数据量是非常大的,如果考虑对海量的数据的存储、备份和还原全生命周期的管理,往往在公有云上成本更低。
2、提高弹性:在公有云上处理大数据,空间和时间灵活性约高,对数据存储和计算资源的要求会随着项目时间越来越长而要求越来越高,而公有云基本能做到想什么时候要就什么时候要,想要多少就要多少。
3、提高容灾性:传统的数据中心的容灾备份往往采用两地三中心的方式,为保证7*24的系统高可用性对系统的要求高,而公有云的IaaS和PaaS的容灾备份机制能实现低成本的低数据丢失率和更短恢复间隔。
4、数据共享更便利:企业应该把自身看成“大数据”价值链中的一部分,那么企业既是贡献者也是受益者,工业大数据的价值可以共享给企业上下游使用,采用统一的公有云平台,促进数据资源的融会贯通,使得数据共享更方便。
大数据上云以后由于网络带宽的限制、对数据处理的时效性要求高、数据存储成本以及模型训练复杂程度多方面的原因,也要求在企业边缘层对原始数据进行一些轻量化处理,在不损失大数据价值性的基础上减少原始数据量。
轻量化的方法
轻量化是在不损失大数据价值性的基础上减少网络传输、存储和训练的数据量,并不是要剔除异常数据。在传统的仪表数据采集的时候都有一个过滤异常数据的操作,会设定一定的阈值去除仪表读数的异常跳变,而轻量化的方法不是采用这样的方法去除异常数据,因为异常的数据有可能对业务分析是有价值的。 轻量化的方法是在业务分析人员以价值需求为导向去发现数据和提取数据,主要是通过采样中的特征选取和数据压缩两种方法。
特征选取是在可采集的样本特征集合中选择预测能力强的最佳子集,剔除重复,简化多个特征之间的相互关联。首先可以对多个特征做相关性分析,如果特征的相关性为1,表示两个特征的变化是完全相同的,通过找出两个特征的线性关系,能够通过一个特征还原另外一个特征,一个简单的例子如果产品的中文名称要求是唯一的,那么这个产品的中文名称和它的编码相关性就是1,不存在多个编码的产品取相同的名称,那么在做数据采集、传输、存储和训练的时候只需要保留产品编码,只需要在结果展示的时候通过对应表的方式找出产品名称。如果在训练样本的时候对特征维度有明确的要求,也可以采用PCA方法对特征进行降维,PCA把原先的n个特征用数目更少的m个特征取代,从旧特征到新特征的映射捕获数据中的固有变异性,尽量使新的m个特征互不相关。还有一些特征之间是有特殊规律可循,比如说某个机台生产的班次和班组的关系是完全按照四班三运转模式来排班,这个时候只需要确认班次就可以推导出执行班组信息,这样的规则如果是固定不变的话,可以在模型训练时候直接处理特征,而不需要另外做采集和储存。
采用压缩算法也是常用的轻量化手段。在带有时间戳的时序性连续变量采集中,随着采集频率的提高数据量也成级数上升,可以通过偏差检测处理和罗旋门压缩过滤,既能反映数据实际趋势,所需要采集、传输和保存的数据也显著减少。下面的三张图简单展示了数据压缩的过程。
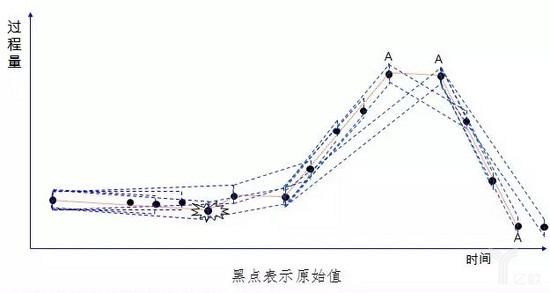
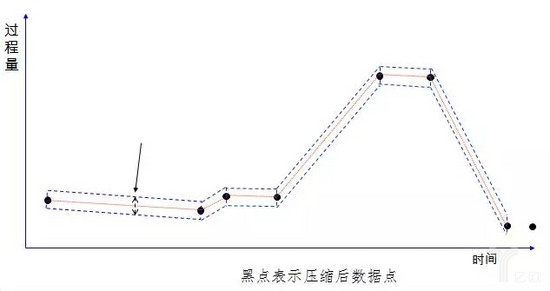

而自编码神经网络是结合了以上两种方式,采用自编码神经网络既可以对特征维度进行降维,也会通过编码方式对数据进行压缩。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,可以通过设定神经网络的隐藏层节点数量来达到数据压缩的目的。比如我们有100个输入特征,可以设定隐藏层节点数量为50,最终输出层还是还原100个输入特征。 模型训练完成后,我们可以用模型的输入层到隐藏层作为压缩算法,把模型的隐藏层到输出层作为解压算法,这样在边缘层进行模型部署进行压缩,在公有云利用模型进行解压。自编码神经网络相对PCA来说可以更好的处理特征之间的非线性关系。
结语
在越来越多的制造业把大数据放在云端进行处理的时候,在网络、存储和计算能力有效的情况下,采用对数据进行压缩和对数据特征进行选取的方法进行数据轻量化处理,以满足数据业务分析需求和处理效率的高效。
一直以来,技术都是推动商业环境进化的重要因素,而目前最热的技术升级趋势,无疑是人工智能。当下,尽管人工智能行业本身已经进入了一个平稳的发展期,但它对于各行各业的赋能却正在以更热烈的姿态进行。
相关阅读:























