








现在一个企业或个人搞个hadoop集群不是难事,除非你想搞上千个节点,难得是如何才能用好这个平台,因此,我们提出要建设一个PaaS平台,让操控数据的门槛足够低,也只有大家都会用了,才有利于形成企业大数据应用的生态,从而更大程度的发挥出大数据的价值。
那么,何谓大数据PaaS?
运营商在进行全网BI系统规划时,会频繁遇到一个问题,各个省公司、各个部门都希望自己搭建大数据平台,到处都缺少人才,甚至都在争抢集成商的支持。随着大数据技术的蓬勃发展,这个问题变得非常严重,关键在于没有规模效益。公司能培养一百名大数据专家已经非常不容易了,但是如果分散在多个省,又分散在各个IT部门(如业务支撑、网管支撑和管理信息支撑系统),那么每个部门只能分到一个人。
所以很自然的想到“能否实现平台和应用分离?”,可否统一搭建一个大数据平台,然后各个单位在平台上做分析模式、搭建自己的应用? 这种集中化的规划,可能是业界第一次提出大数据能力开放平台(PaaS)的概念。
大数据PaaS最重要的就是数据资源的管理,把它与大数据能力一样看待,通通抽象成服务,即一切皆服务,从采集、存储、计算、展现再到管理,下面一张图道尽了一切,这里的DaaS是否可以算作PaaS呢?仁者见仁智者见智了,但如果从目的出发,笔者觉得可以算。
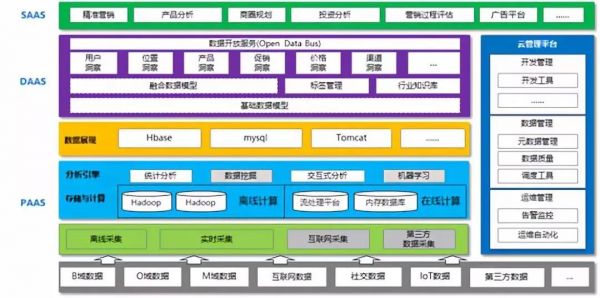
成就大数据PaaS的典范是阿里吧,你看他们的中台,覆盖了PaaS的方方面面,几乎承载了所有数据平台人员的梦想,以下来自《阿里巴巴大数据实践之大数据之路》一书的描述。
数据采集层:
Aplus.JS+UserTrack双剑合璧实现了Web和APP端的采集,TT实现了消息的传输,DataX实现了数据库的同步。
数据计算层:
MaxConpute离线和StreamCompute实时是存储和云计算平台,让其拥有了海量数据处理的底蕴。
数据整合和开发管理:
主要包括OneData和数据开发平台,OneData就是数据仓库建模,数据开发平台就是提供各种开发测试工具,其中的D2(在云端)管开发及调度,SQLSCAN管SQL代码质量,DQC管数据质量,在彼岸管测试,比如数据交换后的表、字段和分布一致性比对等等。
数据开放层:
使应用对底层数据存储透明,将海量数据方便高效地对外开放,阿里叫OneService,主要提供数据查询和实时数据推送服务。
当然,其实PaaS还包括了资源申请,数据赋权等功能,广义来讲就是以上的所有。
理解了大数据PaaS的价值,大家一定对PaaS非常神往,那么,对于一般企业如何打造这类企业级的PaaS平台呢?
第一,自研,但大多时候是找死,当然简单的搞个小工具也就无所谓PaaS了,笔者强调的是企业级,不是部门集市。
第二,全套外包,比如入驻阿里云,享受其提供的大数据PaaS服务,但将失去灵活性,数据安全隐患也成为很多企业不能承受之重。
第三,采购不同的PaaS组件,搭建符合企业自身特点的定制化大数据PaaS,这成为当前很多大型企业的选择。
笔者重点谈的是第三条道路,今天就从管理的视角来谈谈这种模式的一些挑战,很多问题的根源其实不是技术问题,而是建设模式问题,你一旦选择了模式三,就得有足够的思想准备。
1、很难有合作伙伴能够提供全套大数据PaaS组件,这意味着巨大的集成成本
这让我想起了印度的LCA自研飞机,其外形参考法国幻影2000的,而其引擎系统则选用了美国通用提供的F404-GE-F2J3 发动机,另外还有俄罗斯负责参与测试的“卡韦里”涡轮风扇发动机,计算机系统也采用美国的产品,“阿琼”坦克也是如此,其发展时间长达40多年,零配件基本都是进口,印度只是负责组装,即使这样,“阿琼”的造价仍然高达接近1000万美元,而且到目前为止,“阿琼”仍然是一种发展中的坦克产品,它们是否能够正常使用仍是未知数。
大数据PaaS也面临同样困境,其涉及的组件太多了,几乎没有任何合作伙伴能够全套提供,比如数据计算用的是A产品,数据采集用的是B产品,数据开发用的是C产品,数据可视化用的是D产品,每一个产品单独来看都挺不错,但一旦凑一起要形成合力就充满挑战,别说1+1>2,能等于2已经挺不错了,企业在获得灵活性的同时,后续的运营成本很大,这里举二个典型的挑战:
(1)大数据统一的数据管理需要三方产品能按标准吐出元数据,由于各个产品开放程度不同,因此如果你希望能给予运维人员一致的使用体验,能做端到端的影响或溯源分析,估计就很难了,协调的成本太高。
(2)建设大数据PaaS并不是一棍子买卖,后续各个组件都涉及到版本升级,这个时候往往牵一发而动全身,A产品要升级,B产品能否配合测试,C产品能否同步改造,全都是协调工作,而且产生了木桶效应,比如由于XX原因SPARK的版本长期停留在1.5版本,导致很多新功能不能用。
虽然该模式有很大的集成难度,但考虑到能集百家之长,因此成为了很多企业的首选,从大数据PaaS生态的角度看这是好事,但不建议合作伙伴搞什么全套大数据PaaS解决方案,这几乎是不现实的,规划与PPT可以写得很好,但市场会给出答案。
大家说要向BAT看齐啊,它有的我也要有,但要知道阿里是有个阿里云托底的,PaaS组件也是基于阿里云生成,这样PaaS产品的实施难度会直线下降,因此,阿里提OneService是相对容易的。
而大多合作伙伴的产品面对的是开放的生态,你底层要对接的是各种MPP,Hadoop,流处理组件等等,而且要跟着外面的生态与时俱进,因此开始的时候产品其实做不了那么精细,做透一个就相当不易。
比如阿里仅一个开发管理平台就搞出了这么多辅助功能,什么DQC,SQLSCAN等等,我们到现在为止还没实现呢,为什么?因为要做的事情太多了。
2、很难有合作伙伴能够提供技术+体验俱佳的大数据PaaS,而客户这个“白老鼠”间接铸就了他们的成功
为什么合作伙伴一开始很难提供技术+体验俱佳的大数据PaaS?笔者认为根子在于以下两点:
(1)合作伙伴纵然有强大的技术能力,但如果没有足够的数据,他们呕心沥血研发的杰作几乎可以肯定是个半残品,BAT在大数据方面的强大是因为他们的产品是基于自己的大数据慢慢孵化出来的,而大多数合作伙伴没有这个机会,他们的PaaS是规划出来的,模拟的海量数据场景跟真实的数据使用场景有很大的区别,他们的产品一开始非常不成熟。
比如A公司数据采集工具在刚交付客户时,竟然没有基本的统计功能,导致运维甚至无法评估到底有多少比例的接口在第一次上线时抽取失败了,得一个个靠人去看,而这个客户的接口有几千个!
比如B公司在某个小省的客户处顺利升级了产品,但换到某个大省,就爆发了大规模的故障,原因就是大省的日志太多了,List不动了,然后各种超时。
比如C公司由于没考虑到某个客户数据库中的字段中竟然会有文本逗号,这导致了异构数据库间交换的失败,极大影响了生产。
比如阿里的SQLSCAN估计是检测SQL代码质量的,这个功能很重要,可以避免SQL笛卡尔积啥的,但D公司的产品就是提供不了这个功能。
你看,合作伙伴纵有天才的程序员,总有想不到的数据问题和使用场景,而BAT依托于大数据的优势让其打造的产品生态具备天然的优势,因此大家得抱团取暖,有数据差技术的,有技术没数据的,来个优势互补。
(2)呆在实验室的那帮家伙几乎不可能有机会接触到客户的一线维护人员的真实诉求,他们偏重开发更多的功能(意味着更多的收入),提供更强的性能(意味着碾压竞争对手),但当我们欣喜的祝贺大数据PaaS平台上线的时候,却发现自己的一线维护人员要多花1小时去配置一个接口,这到底是怎样一种体验?
一般来讲,B端的产品相对C端不是太强调体验,但笔者觉得还是要具体问题具体分析,讲不讲体验跟B端产品的性质和使用环境有关,具体可参考另一篇文章《为什么就做不好数据产品的体验?》,大数据时代讲究个机器换人,但突然发现需要更多的人去运作这台机器的时候就感觉有点荒唐了,运营运维这种隐性成本其实很高。
A公司,B公司,C公司,D公司都非常拼命,现在的产品越来越好,这对整个大数据产业其实是好事,但也得感谢下那些第一个吃螃蟹的客户,他们给予了海量数据的测试机会,抓出的BUG可谓汗牛充栋,让这些公司的产品得以迭代演化。
如果你的企业需要建设大数据PaaS,但又不想吃螃蟹,那就不要太关注合作伙伴的PPT,应该直接问,在多少企业用过?多大的数据规模?现在有多少人在用?
3、很难有合作伙伴能够兼顾到产品的短期和长期,新时期要在组织架构上进行变革
产品研发的集中化、标准化才能确保合作伙伴用最低的成本获得高的效益,合作伙伴对于大数据PaaS往往有自己的既定演进路径,而客户的需求往往在变,特别是大数据这种正处于从概念向实用的转变中的业务,两者之间的矛盾非常突出。
主要体现在以下三点:
(1)客户提出的需求要进入合作伙伴的研发列表决策流程很长,动辄半年,很多合作伙伴提出要让自己的专家听得见一线的炮声,但也是雷声大雨点小。
(2)B端产品的商务决策流程很长,从客户一线提出需求,到项目经理汇总,再到规划部门,采购部门,信息耗损非常大,再加上合作伙伴的决策流程,到最后,一线的需求往往变了样,一线作为使用人员在整个决策流程中其实是个弱势群体。
(3)合作伙伴规划的大数据PaaS产品功能跟具体的某个客户的需求有出入,客户并不愿意为自己不需要的功能买单,现在功能捆绑销售的问题不少,合作伙伴该如何权衡?哪些该做,哪些不该做。
很多客户受不了,只能另起炉灶,好一点的做法就是搞外挂,要求开放接口,自己搞小应用,不少合作伙伴拒绝开放接口,但这是下策,另一种就是选择其他的替代品,有机会就颠覆你,由于B端产品问题的潜伏期比较长,很多合作伙伴往往浑然不知。
那么,有什么解决办法呢?
笔者近期也在跟大数据PaaS合作伙伴探讨解决方案,有两个建议:
一是必须提升本地PSO的地位,一方面要承担起一线需求对接的职责,并且拥有较强的开发能力,在研发短线支撑不了的时候,进行补位,甚至能承担部分研发的职责,比如率先实现某些功能,另一方面也能传递真实的需求到研发,驱动大数据PaaS产品的成熟,成为感知客户的”晴雨表”和双方关系的”缓冲器”。
二是研发要走大中台的路径,主要做能力沉淀、前后端解耦及开放,为PSO赋能,让其去满足前端应用开发的要求,比如A公司的数据采集平台虽然功能较多,但由于必须前台配置,导致某些轻量级的抽取场景没法用,A又不愿意开放能力,逼得客户只能走外挂。
从这里我们似乎看到了阿里“大中台,小前台”的影子,是的,合作伙伴也可以借鉴这个理念,但不要仅仅局限在技术层面,阿里在实施这个战略的时候,首先调整的是组织架构,如下图:
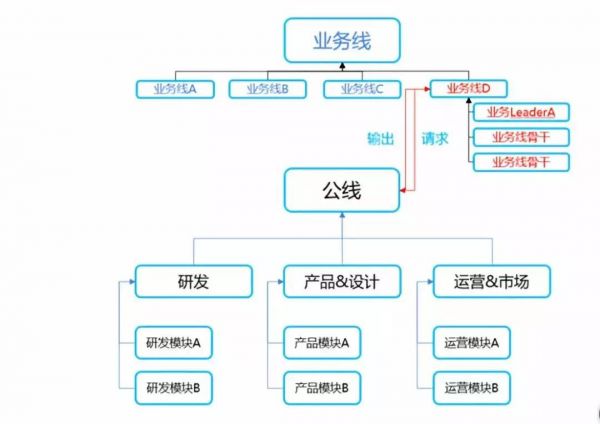
这是一个很有艺术的组织架构,但显然当前大多公司的研发和PSO不是这种中台和前台的关系,研发只是单纯的满足需求,没有中台,无法开放能力,更无从谈起敏捷响应,PSO更多是个配合角色,缺乏话语权。
布莱夫曼2016年出了本书《海星与蜘蛛》,说得就是去中心化的组织架构,集中的组织必须要放权,让听得见炮声的基层组织进行指挥和战斗,别老想着控制,这种手段越来越不好用了。
相关阅读:























