这个问题已经在世界各地的会议和社交聊天的讨论表中浮出水面了-“机器可以打开人类吗?”这个问题经常伴随着《终结者》等电影的场景和视觉效果,但是我们所知道的和所看到的在大数据中使用AI的原因在于,在设计具有更复杂环境的更大规模的系统时,必须考虑某些不确定性和偏差。
机器“感觉”是什么?是什么使他们的行为方式不同于插入大型机的代码?如今,艾萨克·阿西莫夫(Isaac Asimov)的三项法律在定义机器在复杂环境中的行为标准时是否仍然立于不败之地?这些问题的答案在于我们选择定义游戏规则以及机器如何应对突然变化的方式。
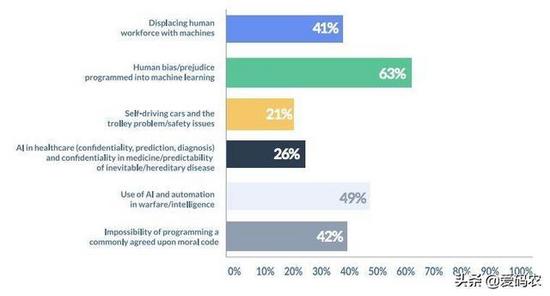
在人工智能研究中,道德偏见是不确定性的一个特殊区域,涉及小装饰品和杠杆,这些小装饰品和杠杆会拉动机器以有时看起来有些奇怪甚至有害的方式运行。随着无人驾驶汽车的兴起和AI驱动的生产方法逐渐占领世界,一个悬而未决的问题再次需要答案。我们如何处理这些机器?
您可能还会喜欢: AI可以自我警戒并减少偏见吗?
偏向简介
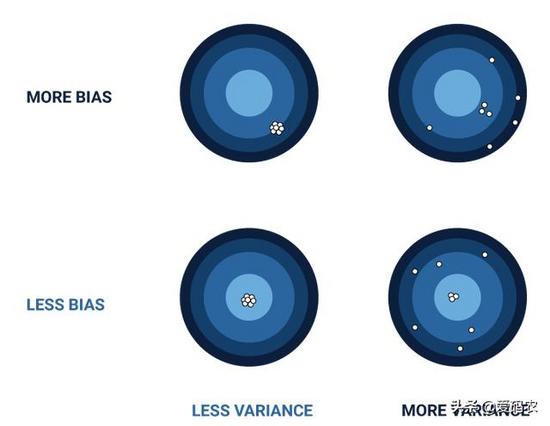
从数据角度来看,偏差和方差与测量值与实际值的接近程度有关。在这种情况下,方差是测量值彼此之间相差多少的度量,偏差是指测量值与实际值相差多少。在具有高精度的模型的高度特定的情况下,方差和偏差都将很小。
但是,这可能反映出该模型对新数据的执行效果有多差。然而,很难实现低偏差和方差,这是各地数据分析师的祸根。对于涉及简单决策而用简单的二进制计算还不够的用例,偏差尤其难以处理。
您可能会想问偏见如何进入系统。而且,如果一台机器无法在不低于人类的临界点上做出决定,那么为什么要首先使用它们呢?要回答这些问题,您需要查看在大数据领域中如何构建模型的一般方法。
首先从执行器和传感器中收集并清除数据,这些数据可为分析人员提供原始数据。这些值然后经过预处理步骤,在此将它们标准化,标准化或转换为除去尺寸和单位的形式。一旦将数据转换为合适的表格或逗号分隔格式,就将其插入到层或功能方程式网络中。如果模型使用一系列隐藏层,请放心,它们将具有激活函数,该函数将在每个步骤中引入偏差。
但是,偏差也可以通过许多收集方法的陷阱进入系统。也许数据没有针对某一组或某类输出进行平衡,也许数据不完整/错误,或者可能没有任何数据开始。
随着数据集变得越来越多且记录不完整,系统肯定有可能用一些预定义的值填补这些空白。这导致另一种假设偏见。
黑匣子难题
许多学者还认为,没有适当的上下文,数字可能不会意味着同一件事。例如,在有争议的《钟形曲线》一书中,作者关于种族群体间智商差异的说法受到了环境约束和差异概念的挑战。但是,如果一个人能够达成这样的解决方案,那么一台机器要花多长时间才能消除这种逻辑上的判断失误?
机会很小。如果机器被送入错误或错误的数据,它将输出错误的值。问题是由AI模型的构建模棱两可引起的。这些通常是黑盒模型,作为数据接收器和数据源存在,而没有解释内部内容。对于用户而言,不能质疑或质疑这种黑匣子模型如何得出结果。此外,结果差异还需要解决其他问题。
由于缺乏对黑匣子运作方式的了解,即使使用相同的输入,分析师也可能得出不同的结果。对于精度不是关键因素的值,这种变化可能不会产生太大的影响,但是数据领域却很少那么慷慨。
例如,如果AI系统无法预测高度特定的参数(例如pH值,温度或大气压),则工业制造商将蒙受损失。但是,当目标是解决诸如贷款兼容性,犯罪再犯甚至适用于大学录取等问题的答案时,AI缺乏清晰的价值将处于不利地位。但是,AI爱好者有责任从另一个角度解决这个问题。
必须解决层之间干扰的方法和规则,以解释每一行代码和系数所代表的含义。因此必须将黑匣子连根拔起并解剖,以了解是什么使机器滴答作响,这说起来容易做起来难。即使看一下最简单的神经网络AI,也足以表明此类系统的原始性。节点和层全部堆叠在一起,各个权重与其他层的权重相互作用。
对于训练有素的人来说,这看起来像是一笔宏伟的交易,但是对于理解机器却几乎没有解释。难道仅仅是由于人类和机器语言水平的差异?是否可以采用一种外行可以理解的格式来分解机器语言的逻辑?
偏见的类型
回顾数据分析中偏差的历史,由于技术不正确或负责分析的实体中预定义的偏差,可能会引入多种偏差。归因于程序员的某些倾向和兴趣,由于模型的定位错误,可能会产生错误的假设和偏见。
这是某些营销分析师在处理潜在客户时常犯的错误。收集软件可提供有关转化者和未转化者的大量数据。大多数人可能会倾向于只针对未转换的潜在客户建立模型,而不是只关注同时针对两种人群的模型。这样一来,他们最终将自己弄瞎了已成为客户的可用数据的丰富性。
困扰AI模型的另一个问题是无法正确分类或错误分类数据,最终导致分析人员陷入灾难。在生产行业中,此类错误属于Type I和Type II类别-前者是在对不属于记录的记录进行分类时,后者是在无法对属于的记录进行分类时。从生产批次的角度来看,质量控制工程师只需对产品的一小部分进行测试,即可迅速提高产品的准确性。它可以节省时间和金钱,但它可能是发生这种假设偏差的理想环境。
在图像检测软件中观察到了另一个类似的示例,其中神经网络扫描图片的损坏部分以重建逻辑形状。图像中对象方向的相似性可能会导致多个问题,这些问题可能导致模型给出令人吃惊的争议性结果。当前时代的卷积神经网络能够分解这种复杂性,但需要大量测试和训练数据才能得出合理的结果。
某些偏差是由于缺乏正确的数据(使用不必要的甚至是不必要的复杂模型)导致的。通常认为,某些模型和神经网络编程仅应在达到统计上显着数量的记录后才应用于数据集。这也意味着必须将算法设计为可重复地及时检查数据质量。
与AI对抗AI
AI偏见的问题解决方案是否隐藏在AI本身内?研究人员认为,改进分析人员收集和划分信息的调整方法非常重要,并且应考虑到并非所有信息都是必需的。
话虽这么说,应该更加强调消除和消除使模型完全不适当的输入和值。数据审计是另一种可以及时检查和消除偏差的方法。与任何标准审核程序一样,此方法涉及彻底清除和检查已处理数据以及原始输入数据。审核员跟踪更改并记下可以对数据进行的改进,并确保数据对所有利益相关者具有完全的透明度。
专门的XAI模型也存在疑问,可以在适当的情况下将其放在问题表中。这些模型涉及非常详细的参数模型开发,其中记录了每个步骤和更改,从而使分析人员可以查明可能的问题并触发实例。
AI也已成为验证模型的准确性和混淆矩阵的前沿,而不是依靠诸如ROC曲线和AUC曲线之类的简单工具。这些模型着眼于在部署数据集之前执行重复的质量检查,并尝试覆盖数据的整体类,而不管分布或形状如何。对于数据集来说,这种预测试的性质变得更加困难,因为数据集的单位和范围的差异在输入中有很大差异。同样,对于与媒体相关的数据,分解内容并将其压缩为数字格式所花费的时间仍然会导致偏差。
但是,由于数据透明性和第三方检查的基础知识有了新的变化,公司至少意识到了出问题了。在模型之间也插入了新的解释器循环,以强调填充大多数AI模型的黑匣子。这些再次由AI模型驱动,这些AI模型经过系统微调以查找不一致和错误。
AI道德失范的几个案例
数据分析人员会熟悉假阴性和假阳性的概念。这些在确定输出方面的差异会导致特殊情况的错误,从而对人员造成不利影响。错误的否定看跌期权是系统错误地将肯定的类别识别为否定的情况。类似地,当否定类别被错误地识别为肯定时,就会出现假肯定。
在实际的大数据研究中,可以更好地理解此类虚假案件的严重性。在使用logistic回归模型对冠心病(冠心病)进行建模的著名案例中,尽管误报率和误报率的准确性很高,但混淆矩阵却产生了大量。对于普通人来说,准确的模型似乎是唯一重要的“成败”检查。但是,即使在数据分析的初期,也很明显,这样的模型会变得平淡无奇,甚至会误诊新患者。
通过收集更多的数据流并清洗列以进行更好的数据标准化来进行权衡。如今,这一步骤已成为该行业的主食。
Uber的自动驾驶汽车在测试阶段遭受撞车并不是业内专业人员关注的唯一危险信号。这些恐惧也扩展到其他领域,例如识别和机器感知。科技巨头亚马逊的模式已经学会发展媒体所谓的对女性的“性别偏见”,因此受到媒体的审查。
在令人震惊的求职者偏见的情况下(先前曾与科技公司的求职者见过),这些模型对女性的应聘工作产生的负面依从性高于男性。另一方面,在诸如Apple之类的科技巨头中也发现了问题,消费者大肆宣传FaceID,允许不同的用户访问锁定的手机。可能有人争辩说,即使对于不同的人,用于识别面部表情以进行检测的模型也可能会产生相似的结果。
工程师坚持消除错误并得出结论认为,可疑输入会产生假设偏差只是时间问题。由于未能整合道德价值观,人工智能在医学界的重大飞跃已经缩回了一个台阶。可以取代旅途中的护士和员工的价值观。这主要是通过解释所有可能数量的案例示例来解决的,在这些案例中,机器可以正确地替代人员并做出完全相同的决定。虽然,哲学专业的学生可能会争辩说,即使人类也没有遵循一套指导方针。有各种道德学派-康德,平等主义者,功利主义者等。这些思想流派如何适应各种伦理难题,取决于个人及其利益。
在著名的拉杆箱中,一个人拉动或不拉动杠杆的倾向纯粹是由该人所处的道德框架决定的。当机器代替决策者时,问责制的问题变得模糊。
最后的话-如何使AI更符合道德
我们对这些系统的容忍度在哪里永恒的问题导致将机器纳入我们的日常活动中。人工智能一直是诸如运输,预测研究,金融投资,安全,通信和生产等救生和支持框架的基础。它已渗透到人类生活的所有重要方面,而没有引起很多反对者的注意。
当AI无法嵌入创建它的人类所遵循的哲学时,就划出了界线。我们与叶夫根尼·扎米亚丁(Yevgeny Zamyatin)和艾伦·图灵(Alan Turing)时代一样遥遥领先,当时机器被认为是公正的。通过教导人工智能具有道德性,在机器中焕发出新的生命是一项挑战,而这一挑战落到了对人类意味着什么的根本问题上。
我们现在知道,要构建一个完善的道德框架,必须将AI精简到其基本要点,并需要采用一种强调上下文的方法来强调结果的质量。与工作场所多元化的基本原理一样,步骤很简单:
密切注意数据。 保持变化但标准化。 让团队不时监视预处理步骤。 在输出中消除任何形式的排除。 删除可能对模型错误或无用的垃圾值。 优化,审核,共享和重新收集结果,并将其纳入模型。 消除交互作用和数据孤岛,并始终进行健全性检查,以最终确定目标是什么。 消除数据孤岛,教AI思考而不是建模思考。 保持对Johari意识的关注。涵盖未知的已知和已知的未知。至于未知的未知数,不幸的是,这种偏见将始终存在。
相关阅读: