








微软推出了最新版旗舰产品关系数据库管理系统SQL Server 2019的预览版,重点介绍了新的大数据功能。
该公司表示,v2019通过将Apache Spark和Hadoop分布式文件系统(HDFS)与SQL Server数据库引擎打包在一起,创建了一个统一的数据平台,帮助数据开发人员无缝地提取,存储和分析大量数据。
微软表示,这种集成对于在大数据时代发展产品至关重要,因为SQL Server的单个实例从未被设计或构建用于处理大数据分析实施中常见的PB级或EB级分析。

微软 SQL Server 2019
此外,微软在其Ignite会议上宣布预览时表示,这种新的大数据集成使SQL Server进一步超越其作为传统数据库的根源。 SQL Server的首席PM经理Asad Khan在 博客文章 中详细阐述了这个和其他细节。 “与每个版本一样,SQL Server 2019通过智能查询处理,数据合规工具和对持久内存的支持,继续为每个工作负载突破安全性,可用性和性能的界限,”Khan说。 “借助SQL Server 2019,您可以承担任何数据项目,从传统的SQL Server工作负载(如OLTP,数据仓库和BI)到AI和高级数据的高级分析。”
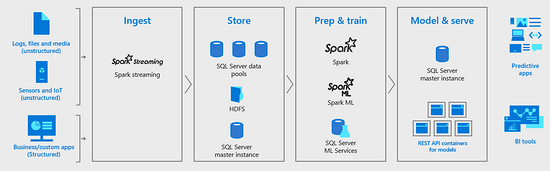
大数据集群提供“完整的AI平台”(来源:微软)。
然而,这是内置的Spark和HDFS功能,突出了预览公告。 微软称这种新的集成架构为“大数据集群”,该公司的首席项目经理Travis Wright 在9月25日 博客文章 中提供了更多信息。 “大数据集群中的SQL Server 2019关系数据库引擎利用弹性可扩展的存储层,集成SQL Server和HDFS,可扩展到数PB的数据存储,”Wright说。 “现在属于SQL Server的Spark引擎使数据工程师和数据科学家能够利用开源数据准备和查询编程库的强大功能,在可扩展的分布式内存计算层中处理和分析高容量数据。“
“可能最明显的采用障碍将是K8s/容器采用数据库工作负载,”Wright回答道。 “公司正在加入这一行列,类似于虚拟化。[另一个障碍是]容器问题。当人们看到将SQL Server可用性组部署到K8中是多么容易,这让人很容易理解。”
此外,新的预览中突出显示了大数据集群中的人工智能(AI)功能,这与微软在奥兰多正在进行的Ignite会议上宣布的许多新产品和功能上强调人工智能功能的重点相呼应。
“SQL Server 2019大数据集群提供了一个完整的AI平台,”微软表示。 “可以通过Spark Streaming或传统SQL插件轻松获取数据并存储在HDFS,关系表,图形或JSON / XML中。可以使用Spark作业或Transact-SQL(T-SQL)查询准备数据并将其输入使用各种编程语言(包括Java,Python,R和Scala)在Spark或SQL Server主实例中进行机器学习模型训练例程。然后可以在Spark中的批量评分作业中运行生成的模型,在T-SQL中存储用于实时评分的程序,或封装在大数据集群中托管的REST API容器中的程序。“
D'Antoni还在单独的总结中介绍了SQL Server 2019中的许多其他新功能,其中 详细介绍 了安全性,数据库性能增强,可用性等。
“SQL Server 2019仍然处于早期预览阶段,”D'Antoni说道,他是一位拥有超过十年经验的建筑师和SQL Server MVP。 “从现在到SQL Server 2019普遍可用的时间还有很多事情要做。但是,很明显,微软继续在数据平台上进行大量投资,并努力使其在服务器和服务器之间保持可用和一致。数据平台,扩大了更广泛的数据服务受众。“
相关阅读:























