








对于深度学习而言,在有很多数据的情况下,再复杂的问题也不在话下,然而没有这么多数据呢?本文作者 Tyler Folkman 针对这一问题,为大家介绍了几个在有限的数据上使用深度学习的方法,让深度学习即便在面临数据稀缺时,也能大展身手。
众所周知,深度学习是有史以来最棒的事情。它能够在大量数据上以低成本解决复杂问题。唯一的问题是你既不在谷歌工作,也不在脸书工作,你的数据是稀缺的,那么你该怎么办?你是能继续使用是深度学习的能力,还是已无计可施?
下面就让我介绍几个在有限的数据上使用深度学习的方法,以及阐述为什么我认为这可能是未来研究中最令人兴奋的领域之一。
一、先从简单的开始
在我们探讨在有限的数据上使用深度学习的方法之前,请先从神经网络后退一步,建立一个简单的基线。用一些传统模型(如随机森林)进行实验通常不会花费很长时间,而这将有助于评估深度学习的所有潜在提升,并针对你的问题提供更多权衡深度学习方法和其他方法的视角。
二、获取更多数据
这听起来可能很荒谬,但是你真的考虑过自己能否收集更多的数据吗?我经常向公司提出获取更多数据的建议,但他们视我的建议如疯人疯语,这让我很吃惊。是的,投入时间和金钱去收集更多的数据是可行的,而事实上,这通常也是你好的选择。例如,也许你正试图对稀有鸟类进行分类,但数据非常有限。几乎可以肯定地说,你可以仅仅通过标注更多的数据来比较轻易地解决这个问题。你不确定需要收集多少数据?对此,你可以在增加额外的数据时尝试绘制学习曲线(相关教程链接),并同时查看模型性能的变化,从而确定所需的数据量。
三、微调
现在假设你已经有一个简单的基线模型,且在获取更多数据上要么不可行要么太昂贵。此时最可靠和正确的方法是利用预训练模型,然后针对你的问题对模型进行微调。
微调的基本思想是取一个一定程度上跟模型所在域相似的非常大的数据集,训练一个神经网络,然后用你的小数据集对这个预先训练好的神经网络进行微调。你可以在 A Comprehensive guide to Fine-tuning Deep Learning Models in Keras 这篇文章阅读更多内容:
文章链接
对于图像分类问题,最常用的数据集是 ImageNet。这个数据集涵盖目标多个类的数百万张图像,因此可以用于许多类型的图像问题。它甚至包括动物,因此可能有助于稀有鸟类的分类。
若需要使用一些用于微调的代码,请参阅 Pytorch 的教程。
四、数据增强
如果你无法获得更多的数据,并且无法成功地对大型数据集进行微调,那么数据增强通常是你接下来的最佳选择。它还可以与微调一起使用。
数据增强背后的思想很简单:在不改变标签值的情况下,以提供新数据的方式改变输入。
例如,你有一张猫的图片,旋转图片后仍然是一张猫的图片,这便是一次不错的数据增强。另一方面,如果你有一张道路的图片,想要预测适当的方向盘转度(自动驾驶汽车),若旋转这张道路的图片将会改变适当的方向盘转度,除非你把方向盘转度调整到适当位置,否则难以预测成功。
数据增强是图像分类问题中最常见的方法,相关的技术可以在这个网站获取。
你也可以经常思考一些创造性的方式来将数据增强应用到其他领域,例如 NLP(相关示例可参考),同时大家也在尝试使用 GANs 来生成新数据。如果对 GAN 方法感兴趣,可以阅读《深度对抗数据增强》(Deep Adversarial Data Augmentation)这篇文章(文章链接)。
五、余弦损失
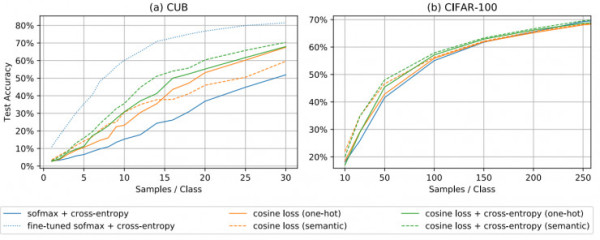
最近的一篇论文《不使用余弦损失进行预训练的情况下在小数据集上进行深度学习》(Deep Learning on Small Datasets without Pre-Training using Cosine Loss)(论文链接)发现,在分类问题中将损失函数从分类交叉熵损失转换为余弦损失时,小数据集的准确率提高了 30%,而余弦损失仅为“ 1 - 余弦相似度”。
从上图中可以看出,基于每个类的样本数量的性能是如何变化的,以及微调对于一些小型数据集(CUB)是多么有价值,而对于其他数据集(CIFAR-100)则没有那么有价值。
六、深入
在一篇 NIPS 论文《小数据集的现代神经网络泛化》(Modern Neural Networks Generalize on Small Data Sets)(论文链接)种,作者将深度神经网络视为集合。具体来说,即「与其说每一层都呈现出不断增加的特征层次,不如说最后一层提供了一种集成机制。」
从中得到的关于小数据的益处是确保你建立的深度网络能利用这种集成效应。
七、自编码器
现在已有通过采用更多优化的起始权重成功使用堆栈自编码器对网络进行预训练的案例(该案例可参考论文「Using deep neural network with small dataset to predict material defects」)。这样可以避免局部优化和其他不良初始化的陷阱。不过,Andrej Karpathy 建议不要对无监督预训练过度兴奋(相关文章可参考:http://karpathy.github.io/2019/04/25/recipe/)。
如果你需要复习自编码器相关知识,可以看看斯坦福大学的深度学习教程(网址)。自编码器的基本思想是建立一个预测输入的神经网络。
八、先验知识
最后一点是尝试找到结合特定领域知识的方法,以指导学习过程。例如,在论文《通过概率程序规划归纳进行类人概念学习》(Human-level concept learning through probabilistic program induction,论文链接)中,作者构建了一个能够在学习过程中利用先验知识从部分概念中构造整体概念的模型,这样的模型能够实现人类水平的性能,并超出了当时的深度学习方法。
你也可以使用域知识来限制对网络的输入,以降低维度或将网络体系结构调整的更小。
我将其作为最后的选择,是因为结合先验知识可能是一个挑战,通常也是最耗费时间的。
九、让深度学习在小数据上也能变得很酷
希望本文为你提供了一些关于如何在有限的数据上使用深度学习技术的思路。我个人认为,这是一个目前没有得到足够讨论的问题,但它具有令人非常兴奋的意义。
大量问题的数据非常有限,因为获取更多的数据要么非常昂贵要么不可行,就比如说检测罕见疾病或教育成果。找到方法来应用深度学习等好的技术来解决这些问题是非常令人兴奋的!正如吴恩达(Andrew Ng)也曾提到:
【凡本网注明来源非中国IDC圈的作品,均转载自其它媒体,目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。】























