








经典版的MapReduce
所谓的经典版本的MapReduce框架,也是Hadoop第一版成熟的商用框架,简单易用是它的特点,来看一幅图架构图:
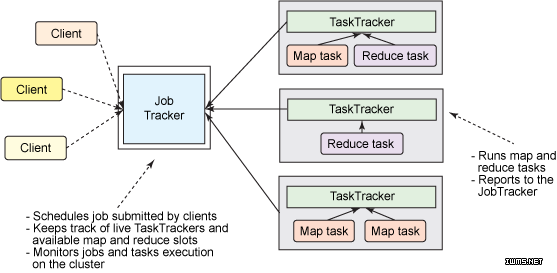
Hadoop上面的这幅图我们暂且可以称谓Hadoop的V1.0版本,思路很清晰,各个Client提交Job给一个统一的Job Tracker,然后Job Tracker将Job拆分成N个Task,然后进行分发到各个节点(Node)进行并行协同运行,然后再讲各自的运行结果反馈至Job Tracker,进而输出结果。
但是,这种框架有它自身的限制性和局限,我们来简单的分析几点:
1、 单点故障 ,首先,单点故障也是最致命的一点,从上图中可以看到所有的Job的完成都得益于JobTracker的调度和分配,一旦此节点宕机就意味着整个平台的瘫痪,当然,在实际中大部分通过一个JobTracker slaver来解决。但是,在一个以分布式运算为特性的框架中,将这种核心的计算集中与一台机器不是一个最优的方案。
2、 可扩展性 ,同样,在上面的架构图中可以看到,Job Tracker不但承载着Client所提供的Job和分发和调度,还需要管理所有的Job的失败、重启,监视每个Node的资源利用情况,实现原理无非就是Heartbeat(心跳检测),随着Node的数量的增加,Job Tracker的任务就会变得越来愈大,在疲于应付各个子节点运行检测的同时,还要进行新的Job的分发,所以这种框架官方给出了限制节点数(<4000 节点)。
3、 资料浪费 ,在传统的架构中,每一个Job的分配,是通过Node资源的数量进行分配的方式,显然这种分配方式不能动态的实现负载均衡,比如,两个大的内存消耗的task调度到了一个Node上,这也就意味着状态机器压力很大,而相应的某些节点就比较轻松,显然在分布式计算中这是一种很大的资源浪费。
4、 版本耦合 ,其实这一点也是影响一个平台做大的致命缺陷,以上的架构中,MapReduce框架有着任何的或者不重要的变更(比如BUG修复、性能提升或某些特性),都会强制进行系统级别的升级更新。而且,不管用户是否同意,都得强制让分布式系统的每一个用户端进行更新。
以上四点,是V1.0框架之上所带来的局限性,总结的来看,问题主要是集中在中间节的主线程Job tracker上面,所以解决这个线程的问题,基本也就解决了上面所提到的性能浪费和扩展性等诸多问题。
下面我们再详细的分析下Job Track在MapReduce中的详细职责,解决扩张性的问题无非就是责任解耦,我们来看一下:
1、管理集群中的计算资源,涉及到维护活动节点列表,可用和占用的Map和Reduce Slots列表。以及依据所选的调度策略可用的Slots分配给合适的作用和任务
2、协调集群中运行的任务,这涉及到指导Task Tracker启动Map和Reduce任务,监视任务的运行状态,重新启动执行失败任务,推测性能运行缓慢的任务,计算作业计数器值的总和,等等。
看看,JobTrack是不是很累…… 这样的安排放在一个进程中会导致重大的伸缩性问题,尤其是在较大的集群上面,JobTracker必须不断的跟踪数千个TaskTracker、数百个作业,以及数以万计的Map和Reduce任务,下面来个图看看:
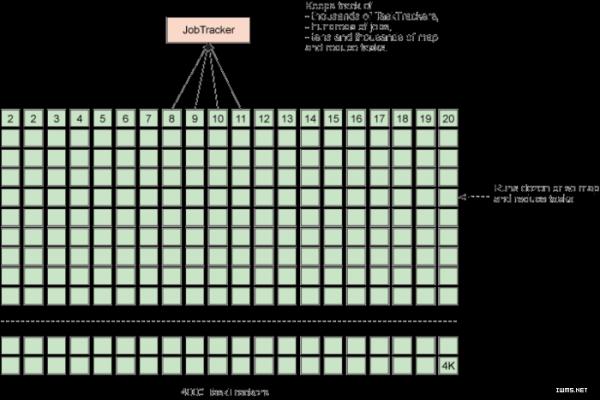
上图中显示了一台比较忙的Job Tracker在忙碌的分配着任务……
所以,分析到此,似乎解决问题的方式已经呼之欲出了: 减少单个JobTracker的职责!
既然减少JobTracker的职责,也就意味着需要将不属于他的职责分配给别人去干,经过上面的简述,我们基本上可以将JobTracker的职责分为两大部分:集群资源管理和任务协调。
这两大任务之间,显然集群管理的任务要更重要,它意味着整个平台的性能的健壮和平台的扩展性,而相比较,任务协调之类的事情就可以分配到某一个下属的Node来干,并且由于每一个Client所提到的Job分配过程和执行过程而言,分配过程显得短暂并且灵活。
通俗一点的讲: 就是将上面架构中的JobTracker责任进行剥离,让它就负责整个平台的资源管理就可以了,至于任务的分配和协调就交给属下(Node)来干就好了。就好比一个公司来个活,大Boss只负责整个公司的资源管理,而这个活就扔给相应的部分就可以了。
经过上面的分析,好像基本下一个版本的架构优化方式也基本明确,我们来接着分析Hadoop的新一版的架构。
新一代的架构设计YARN
来看一下官方的定义:
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
经过第一部分的分析,我们基本已经确认了将以前的JobTracker这个主线程的责任更改为整个集群的资源管理和分配。从这一点讲这里如果这个线程的命名还是JobTracker显然就不合适了。
所以在新一般的架构图中他的名字变成了ResourceManager(资源管理),然后这个名字更适合它的职责。
我们先来一幅图看看

哈,长得基本和上一代的架构图一样,只是责任有了明显的分离,我们来分析一下,首先来确定一下图中的名词:
1、ResourceManager(RM)全局群集资源管理器
2、ApplicationMaster(AM)专用的JobTracker,途中可以看出,目前已经将JobTracker的职责分离到了Node中了。
3、NodeManage(NM)管理各个子节点,代替以前的TaskTracker,不过功能基本类似,只不过添加了一个每个节点的的自管理功能,也是对RM的责任分担。
4、Containers,用Application来提到以前的MapReduce作业,而承载Application的容器就为Container,目的是为了更多应用能运行在Hadoop平台下,为了以后的扩充。
我们来简述一下,整个框架的运行流程。
在YARN构架中,一个全局的ResourceManager主要是以一个后台进程的形式运行。它一般分配在一个独有的机器上,在各种竞争的应用程序之间独裁可用的集群资源。ResourceManageer会追踪集群中有多少可用的活动节点和资源,协调用户提交的那些应用程序在何时获取这些资源。
ResourceManager是唯一拥有此信息的进程,所以它可通过某种共享的,安全的,多租户的方式制定分配(或者调度)决策(例如,依据应用程序的优先级,队列容量,ACLs,数据位置等)
在用户提交一个应用程序时,一个称为ApplicationMaster的轻量级进程实例会启动协调应用程序内的所有任务的执行。包括监视任务,重新启动失败的任务,推测的运行缓慢的任务,以及计算应用程序计数值的总和。这些职责以前就是JobTracker.现在已经独立出来,并且运行在NodeManager控制的资源容器中运行。
NodeManager是TaskTracker的一种更加普通和高效的版本,NodeManager拥有许多动态创建的资源容器,容器的大小取决于所包含的资源量,比如:内存、CPU、磁盘和网络IO.但是 目前仅支持内存和CPU(YARN-3)。 其实这里平台提供的一个接口,方便后续的扩展,未来可使用cgroups来控制磁盘和网络IO.
其实,简单点讲,NodeManager是一个高度自治的内在节点,包括节点内的JobTracker.
我们再来看另外一幅图,来详细的看一下,YARN内新的Job内在流程在各个节点(Node)中的流转:
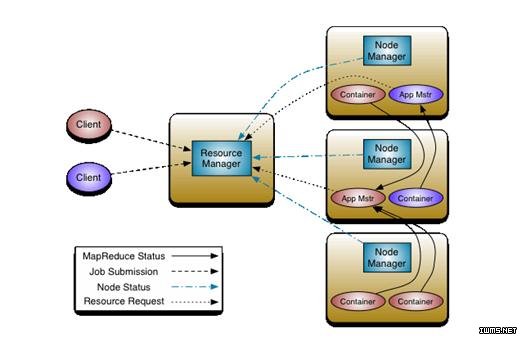
从这幅图中可以看到,和之前的第一版的架构图相比,是多了后面节点之间的交互,因为,在新的结构图中我们将JobTracker的职责下放到NodeManager中的ApplicationMaster中了,也就是会在ApplicationMaster中进行传统的Map-Redurce的分发,所以会造成各个不同的Noder之间发生交互。
当然,这所有的过程都会他们的老大ResourceManager进行调度和管理。
以上的架构,在Hadoop版本中称之为MRv2.
我们来总结一下,这个架构所解决的问题:
1、更高的集群利用率,一个框架未使用的资源可由另一个框架进行使用,充分的避免资源浪费
2、很高的扩展性,采用了这种责任下方的架构思路,已经解决了第一版4000node的限制,到目前可以充分的扩展资源。
3、在新的Yarn中,通过加入ApplicationMaster是一个可变更的部分,用户可以针对不同的编程模型编写自己的AppMst,让更多的编程模型运行在Hadoop集群中。
4、在上一版框架中,JobTracker一个很大的负担就是监控Job的tasks运行情况,现在,这个部分下放到了ApplicationMaster中。
除了上面几点之外,我们特别来分析以下,在新版框架中的ResouceManager的功能亮点。
上个图看看:
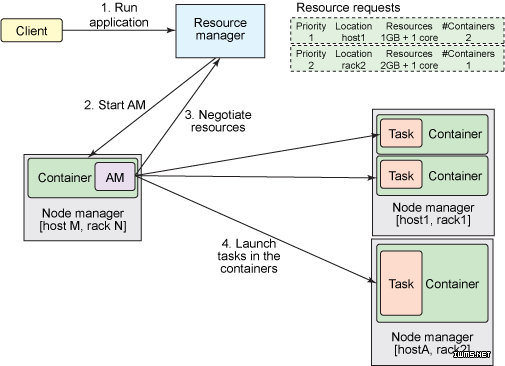
当一个Client提交应用程序的时候,首先进去的就是ResourceManager,它维护着集群上运行的应用程序列表,以及每个活动的NodeManager上的可用资源列表。ResourceManager首先要确定就是那个应用程序可以运行此Job,会存放到相应的Container中去,当然这里会分配一部分的集群资源,这一部分资源的选择会受到许多的限制,比如:队列容量,ACL和公平性。下一步就是另外一个可插拔的组件Scheduler来下发任务( 这里不是分发! ),Scheduler近执行调度,不会对应用程序内的执行过程有任何监视, Scheduler就好比秘书一样,将大Boss(RM)分配的任务传递到相应的部门 .
然后,就是部门的领导(ApplicationMaster)来分配任务给员工(DataNode)了,而这个分发的过程就是Map-Redure,所以在这个过程中,ApplicationMaster负责此应用程序的整个周期,当然在运行过程中,它可以跟老大(RM)进行一些相应的资源需求,比如:
1、一定量的硬件资源,比如内存量和CPU份额。
2、一个首选的位置,比如某台Node,通常需要制定主机名、机架名等。
3、Task分配后的优先级。
然后,找到相应的资源之后,就开始甩开膀子进行任务的完成,而这些跑批则发生在(Node)中,但是Node中也有它自己的小队长(NodeManager),它负责监视自己node种的资源使用情况,比如,自己的任务比当初分配的少,提前完成了,它会结束该容器,释放资源。
而在上面的过程中,ApplicationMaster会竭尽全力协调容器,自动所需要的任务来完成它的应用程序,他会监视应用程序的进度,重新启动失败的任务,以及向Client提交应用程序的报告进度。应用程序完成后,ApplicationMaster会关闭自己并释放自己的容器。
当然,这个过程之中,如果ApplicationMaster自己挂掉了,这时候ResouceManager会重新重新找一个领导(新的容器中启动它),直至整个程序完成。
结束语
Hadoop是一个非常牛掰的分布式架构平台,它的优越性我想不需要我跟大家分享,很多成功的案例都已经在暗示着我们, 未来所谓的大数据,所谓的互联网+,所谓的云……都会找到它的立脚点。























